Anchor Free (After Faster R-CNN)
Introduction
目标检测: 在RCNN之前--滑动窗口+图像金字塔 RCNN,SSD,YOLO之后--Proposal Region+Anchor based 在18年到现在,新出现了一系列方法,都是Anchor Free的,以直接检测点(矩形包围框的角点、中心点等)为思路来做目标检测。
Why Anchor Free?
Anchor本质上还是在feature map上用不同大小的box遍历,开销很大,也有很多浪费。
由于基于遍历,所以往往得到的box里面的“正样本”(即实际检测出foreground的anchor)很少,迫使训练时使用大量“负样本”。同时anchor box的大小怎么确定也很难说,针对不同的物体,大小往往是差异很大的。
为此我们引入了CornerNet
CornerNet: Detecting Objects as Paired Keypoints
Inspiration
对于instance object detection,我们需要tag图片的每一个像素,但是对于图片检测而言,其实我们需要的只是一个简单的box用来框住foreground而已,因此为什么不直接回归box(即box的两个对角点)。
CornerNet
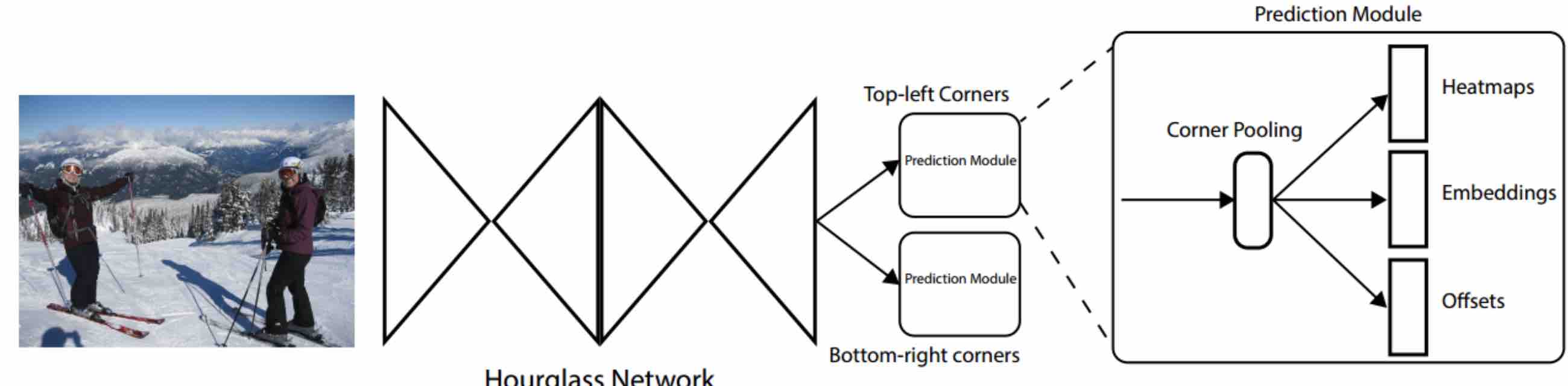
网络结构:
Image->Hourglass Network提取特征->Prediction Module
Prediction Module分成左上角/右下角两个点,同时对每个点的的提取先经过Corner Pooling,再处理成三个特征:Heatmaps,Embeddings和Offsets。
Heatmaps和Offsets表示角点的位置,Embeddings用于进一步计算来合并同一个框的两个点。(原文解释同一个物体两个角点的Embedding vetor距离较小)
文章使用了Hourglass网络(最早提出在姿态检测),呈沙漏状,包括downsampling+upsampling。
HouglassNet
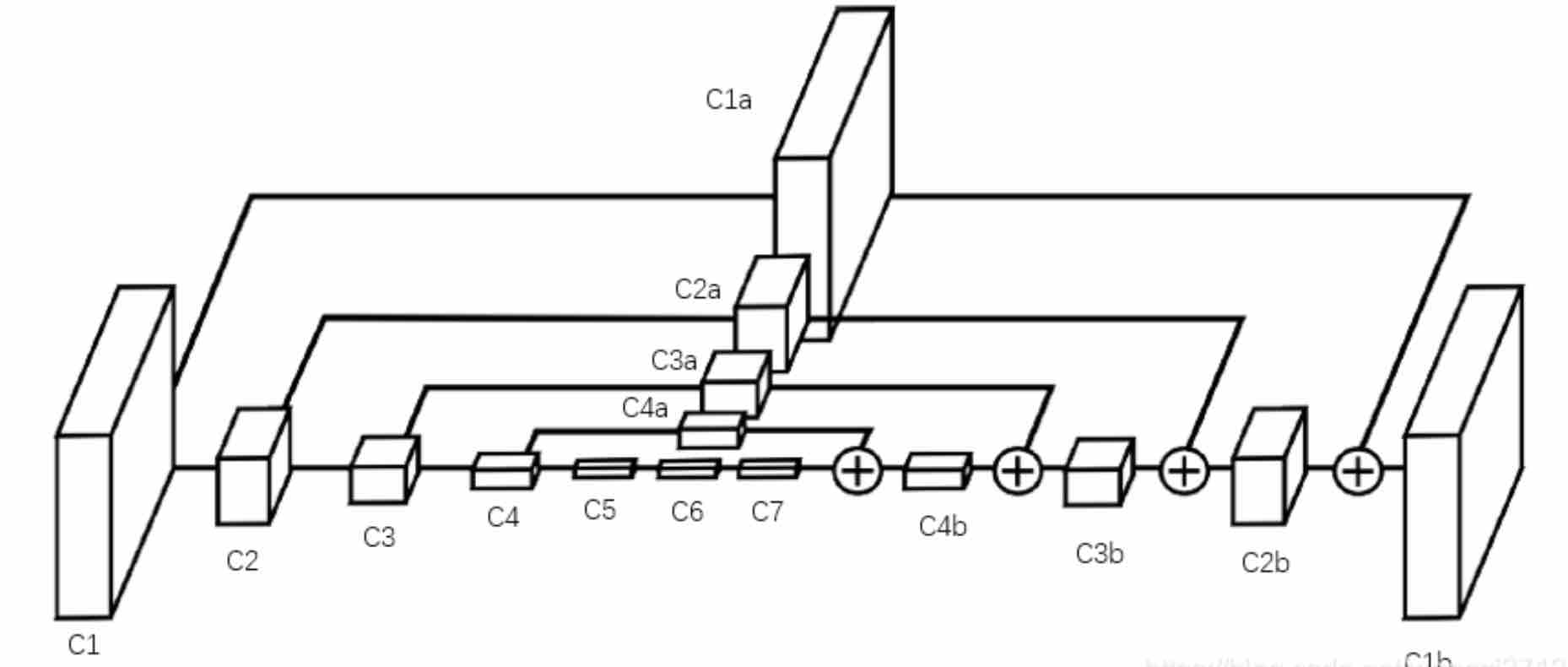
先经过Cov+maxpooling,再通过skip layer重新让网络恢复大小。
这里恢复大小的操作非常简单:C7经过上采样得到C4',此时C4'与C4的大小一致,通过elementwise的相加(即将C4和C4'相对应的每个元素相加)得到C4b。(note:C1a=C1,仅为其保留的副本)
这样将feature map层层叠加后,得到最后一层的feature即保留了所有层的信息,又和输入原图大小一致,那么就可以通过1x1卷积生成代表关键点概率的heatmap。
又因为单个hourglass的特征提取能力的特征提取能力有限,为此在本文中使用两个网络连续堆积。
同时作者对hourglass做出了改进--不用maxpooling降维,而是用stride=2的卷积来实现降维。
Residual Block
hourglass module之前,需要将image降维为1/4。本文采用了一个7x7卷积和一个残差单元。
Residual Block本质是一个跳层网络
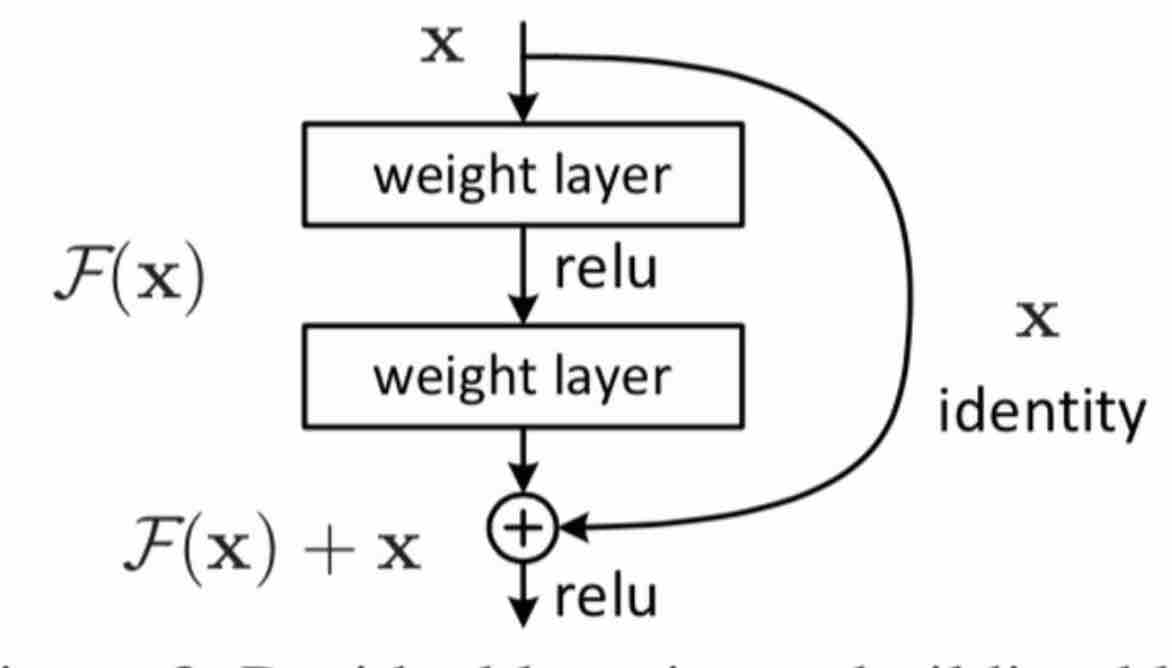
残差连接使得信息前后向传播更加顺畅。
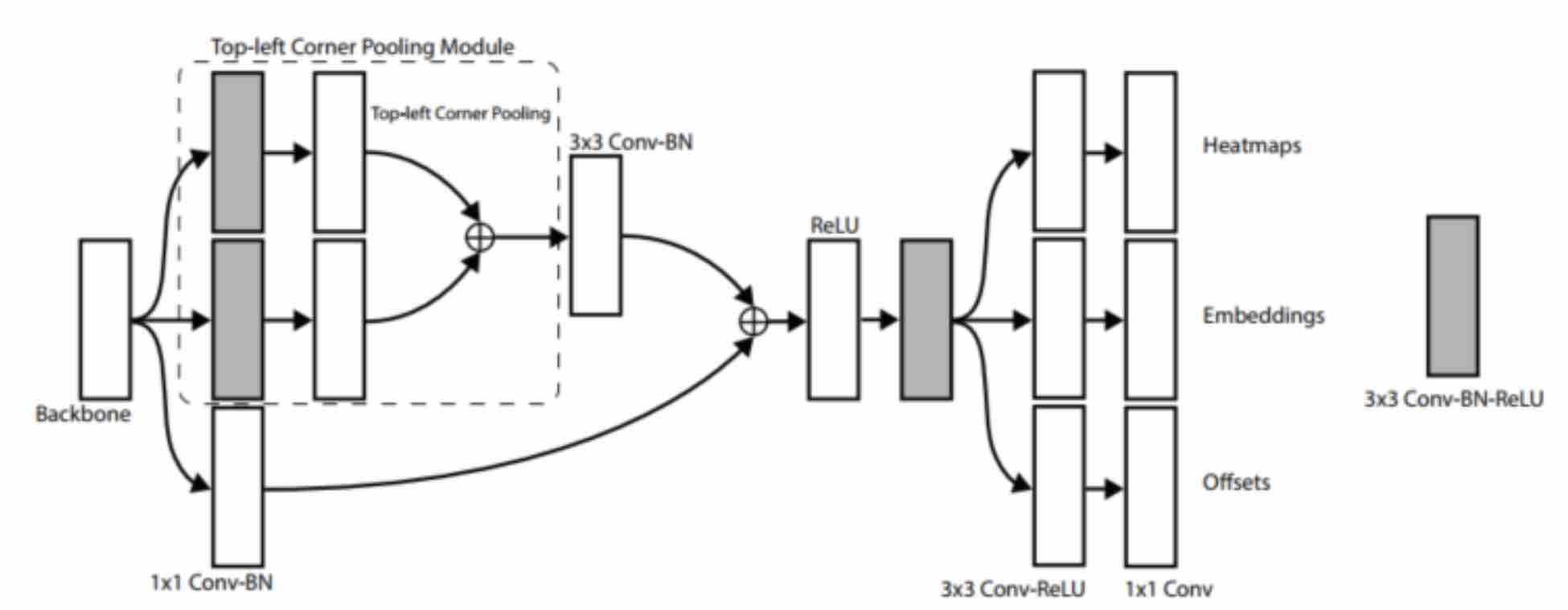
在本文中预测结构的前半部分就有类似这种结构:
Backbone FeatureMaps分为三路:上两路路经过3x3 Cov,Corner Pooling,合并为一路后Batch Normalization;下路只经过Batch Normalization,最后和上两路合并的结果再合并。
Corner Pooling
为了使卷积网络更好地定位边界框的角点,作者引入了corner pooling。
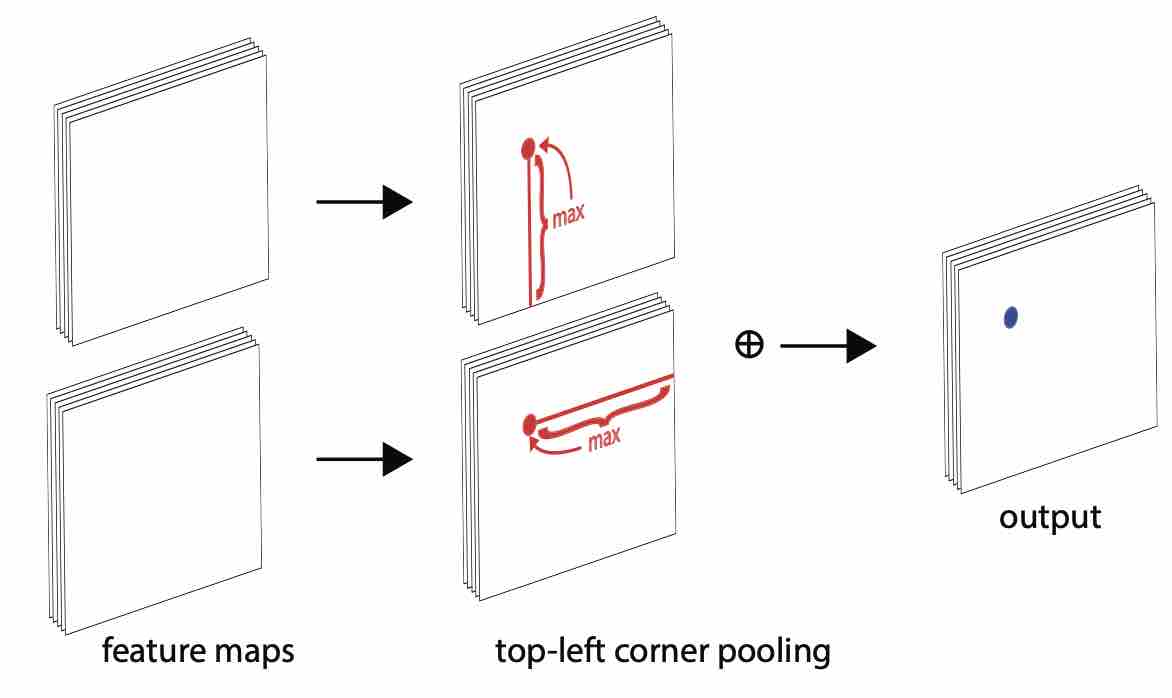
如何定位左上角点呢?人眼在看到左上角点时需要往右和往下看来确定这个点是不是一个物体的左上角点。
当求解某一个点的top-left corner pooling时 ,就是以该点为起点,向右看遇到的最大值以及向下看最大的值之和。
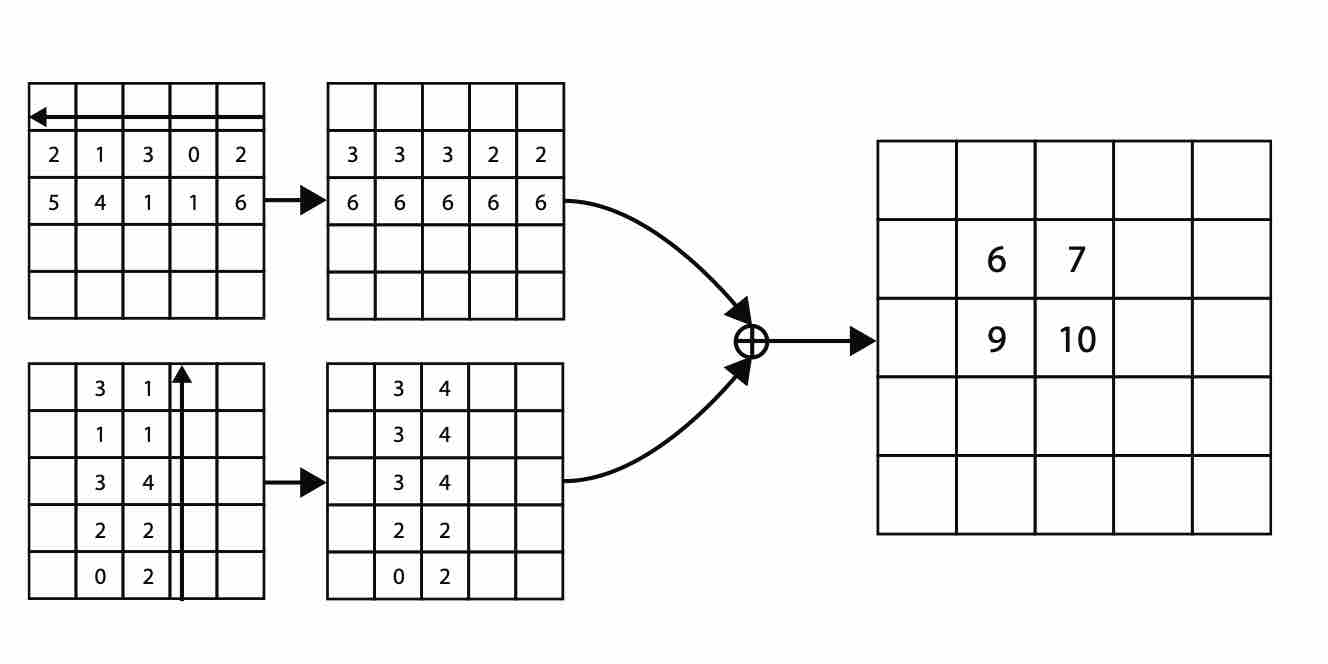
但是实际操作中却是从右往左,从下往上看。这样做有一个好处:我们先按照这个逻辑遍历整张图,之后我们想要填充某个点的top-left corner pooling时只需要直接对照之前得到的结构填充就可以了,而不用再次遍历。
Corner Pooling引入了一定的人类先验知识,在实验中使得效果大大提升。
Why corner pooling?
在目标检测的任务中,object的corner往往在object之外,所以corner的检测不能根据局部的特征,而要对该点所在行的所有特征与列的所有特征进行扫描。
Batch Normalization (BN)
BN是神经网络中一种特殊的层,在原paper中,BN被建议插入在(每个)ReLU激活层前面。
对于batch size=m,在前向传播过程中,网络中每个节点都有m个输出,BN希望对这m个结果归一化再输出:
简单说是将输入的\(x\),先变化成 zero mean unit variance的分布\(\hat x\)(Standardization),再变成\(y=\gamma * \hat x _i + \beta\)(scale and shift),由此将\(x\)变成均值\(\beta\)方差\(\gamma\)的\(y\)(均值、方差待学习)。
Bottom-up Object Detection by Grouping Extreme and Center Points
ExtremeNet与CornerNet不同在于
关键点选取不同:ExtremeNet的关键点选取为Object的最顶点,最底点,最左点和最右点,而不是包围框的左上角点和右下角的点
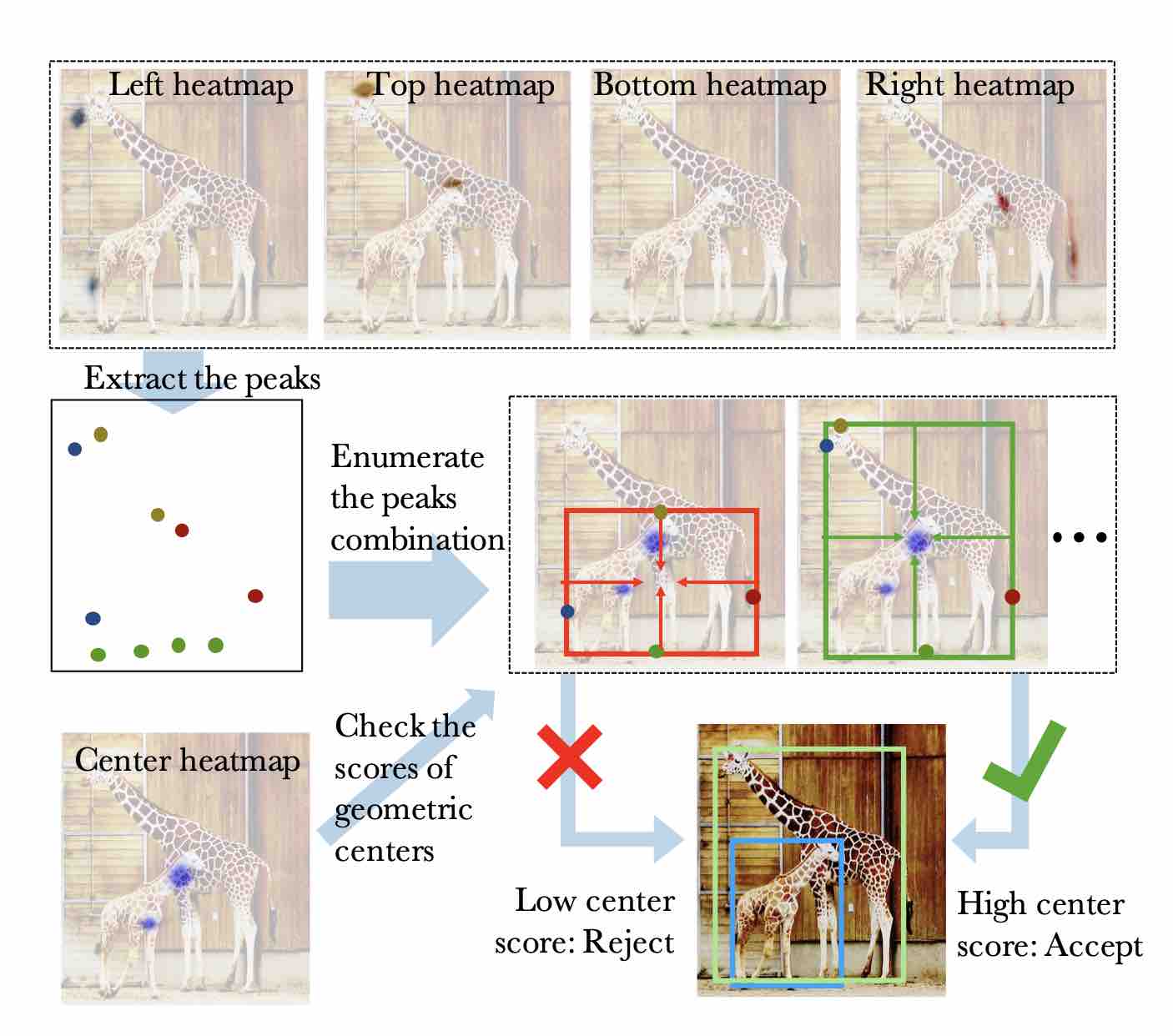
Grouping方法不同:ExtremeNet不需要学习Embddings,直接把所有的候选点集合做暴力穷举,再结合几何规则和中心点Heatmap找出包围框(也可以是多边形)
ExtremeNet得到的信息更丰富:ExtremeNet可以得到目标不多边形包围框,比一般的矩形包围框可以提供更多的关于目标的信息。
Inspiration
使用corner已经能达到比较好的效果,但是cornernet所能获得的只有box,而box的顶点(左上角、右下角)往往实际上距离物体本身已经很远了,因此box顶点的特征就会不明显。而且面对本身不重合的物体,box可能会重合,如此一来对物体之间的分割效果就会很差。
ExtremeNet
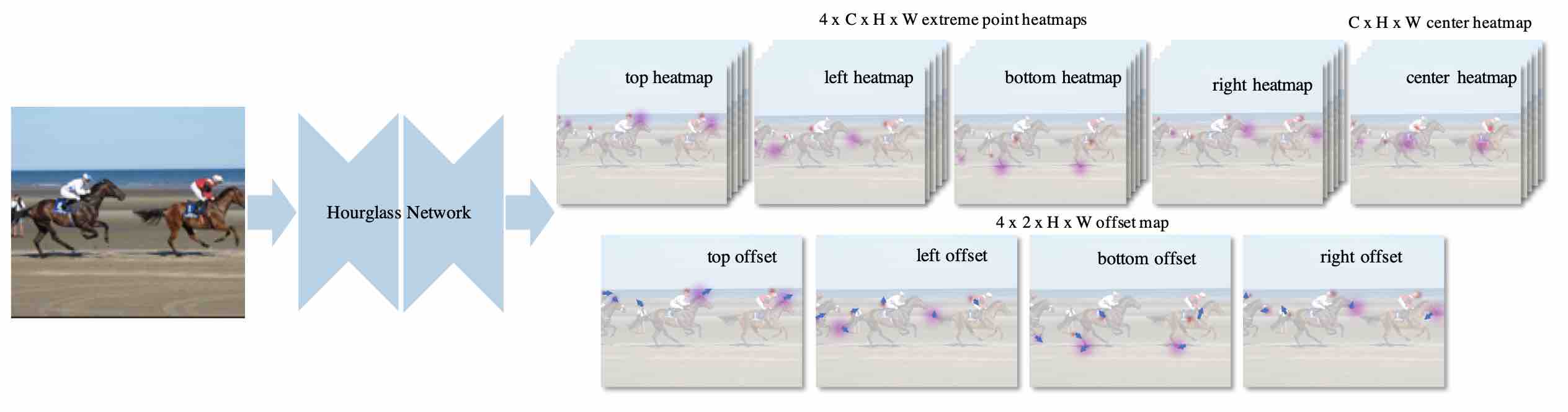
本文作者需要找到5个heatmap,分别是4个物体边缘(extreme),和一个中心(center)。
在如何Group point上,作者放弃了使用Embedding vector,而是先遍历所可能的extreme point的组合,然后仅保留与center point相吻合的组合。
CenterNet: Objects as Points
Inspiration
构建模型时将目标作为一个点——即目标BBox的中心点。
中心关键点一般都是落在了目标内部,其特征相较于之前两篇与物体本身相关性更好。
由于之前的两篇是通过group point来实现box,因此需要NMS(非极大值抑制)来破除重复,和Embedding来确定哪些点属于同一个object。CenterNet则都不需要,效率更高。
CenterNet
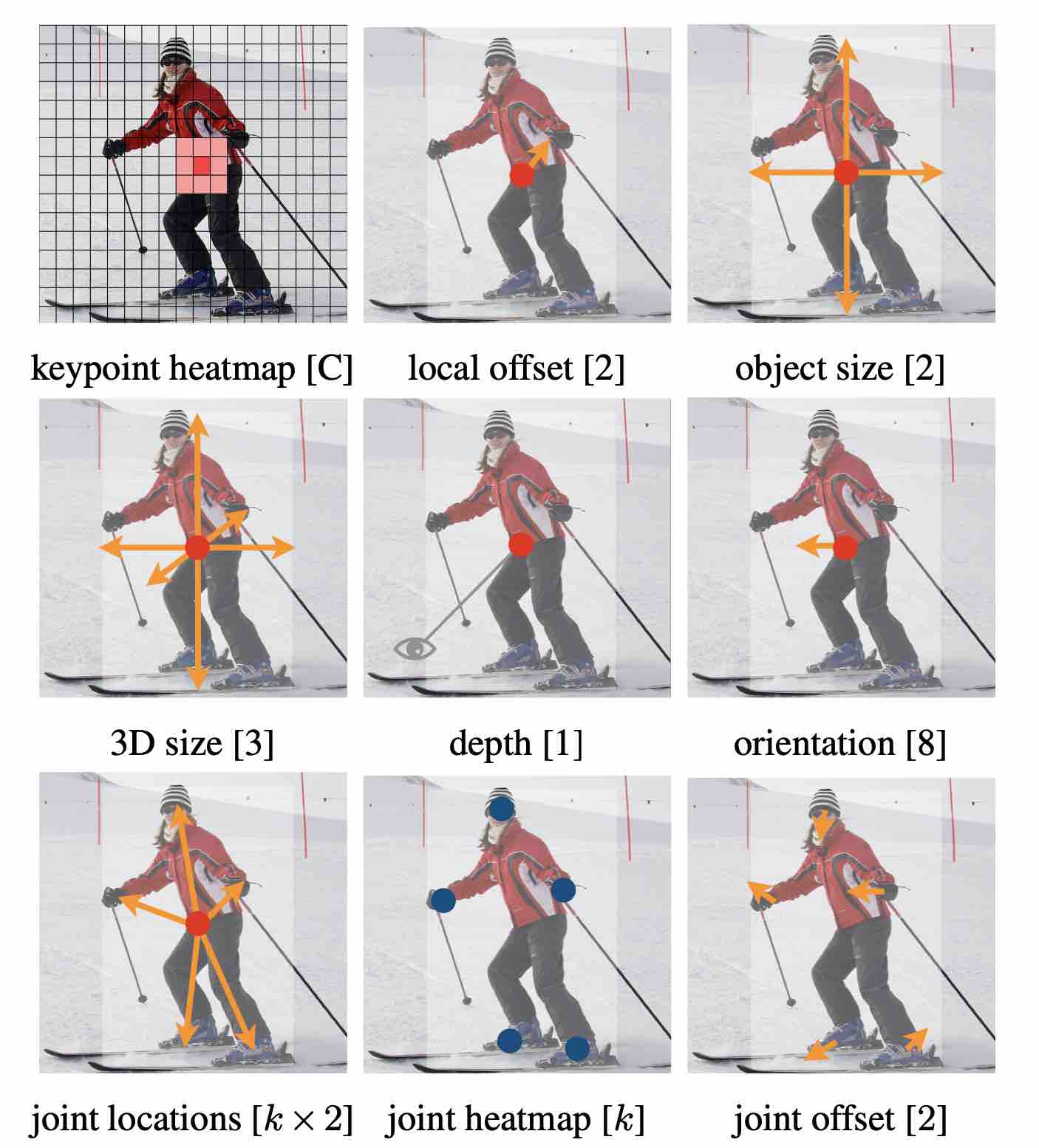
Outputs of our network for different tasks:
top for object detection; middle for 3D object detection; bottom: for pose estimation. All modalities are produced from a common backbone, with a different 3 × 3 and 1 × 1 output convolutions separated by a ReLU.
CenterNet:Keypoint Triplets for Object Detection
Inspiration
对于cornernet来说,box的选择正确率很低,平均上每生成100个预测框,有37.8个和真值的IoU<0.05。因此作者尝试使用Triplet keypoint--左上角、右下角+中心点。
CenterNet
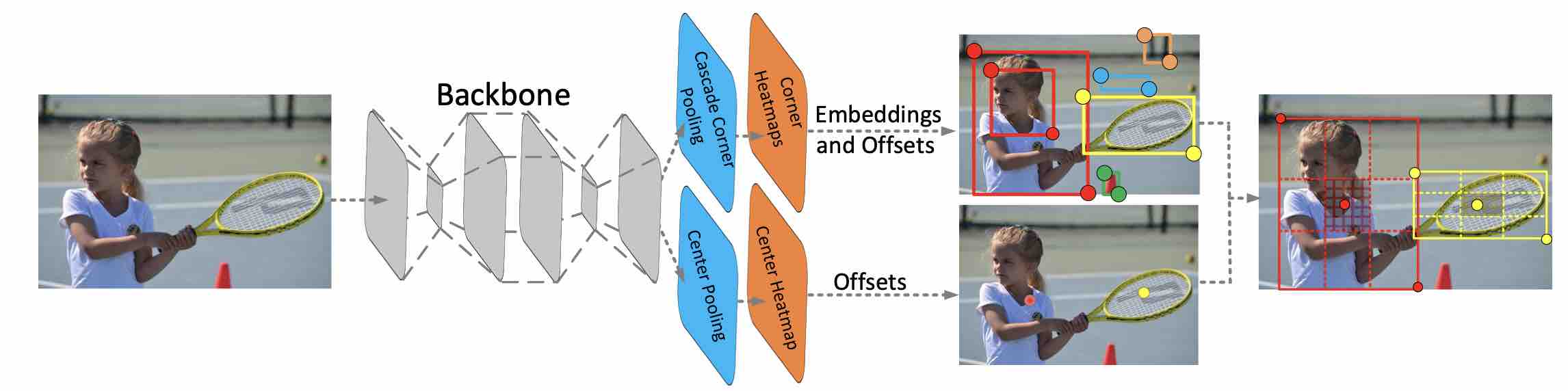
每个box用一个中心点和一对对角点坐标来表示。
如何得到top k boxes:
- 选择top k中心点
- 根据offset,将中心点重新映射到input image
- 为每个box定义一个中心区域(central region),检查中心区域是否包含上述得到的中心点(中心label应该与box label相同)
- 若中心区域检测到中心点,保留box。box 分数改变为三个点的平均分。若无,则移除。
Central Region
中心区域的确定对于结果非常关键,为此central region大小需要与box大小相关。
note:中心区域对于小的边界框倾向于产生一个相对较大的中心区域,而对于大的边界框倾向于产生一个相对较小的中心区域。

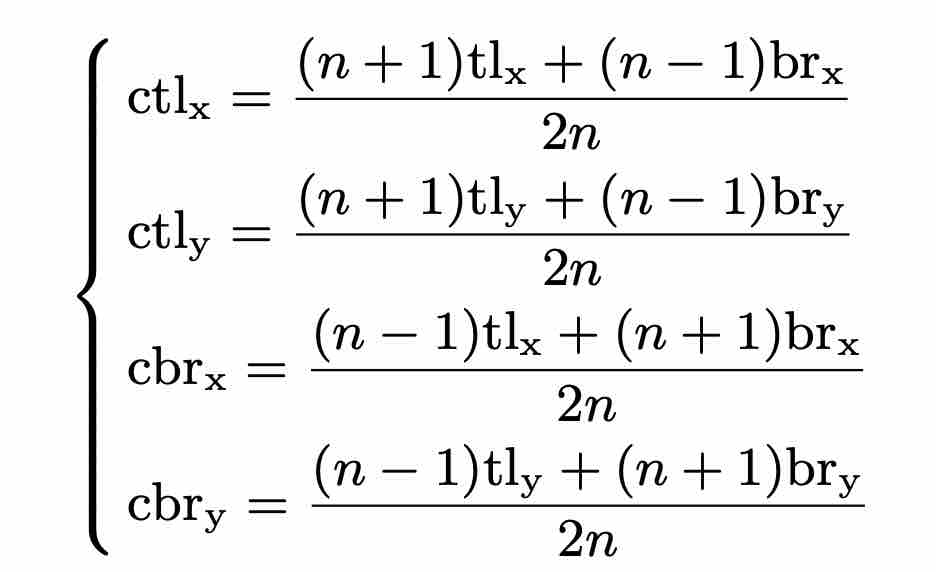
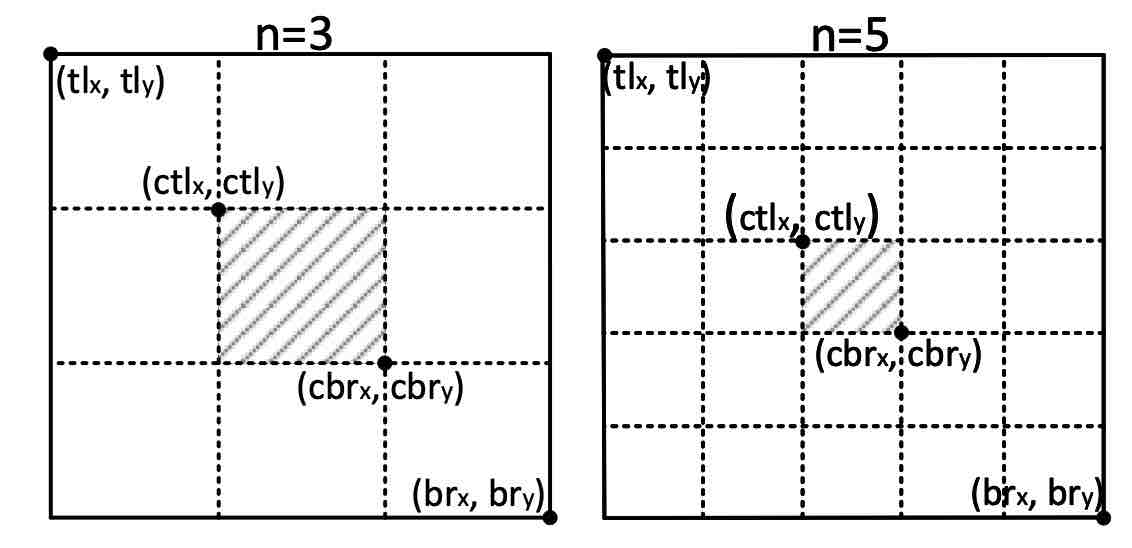
bounding box尺寸小于150时,n=3,当大于等于150时,n=5。
公式比较复杂,但其实只是为了满足大box小center region,小box大center region而已。
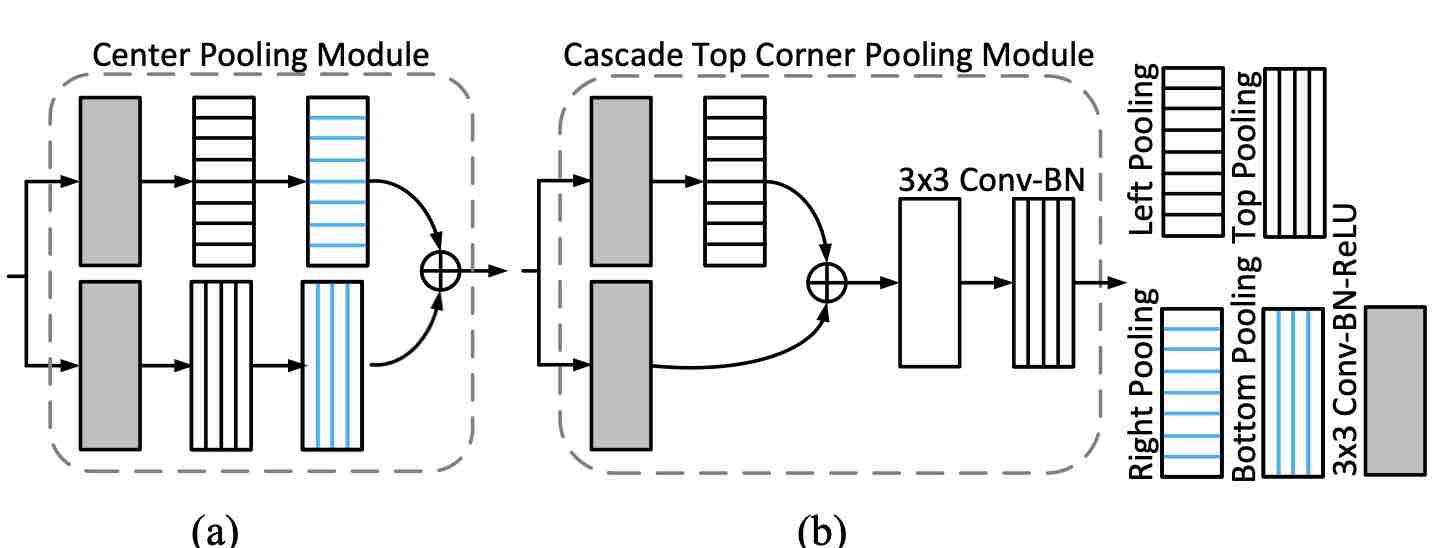
Center Pooling
对于一整个物体,物体的语义特征点和物体中心点很可能并不重合。为了充分学习语义信息,使用center pooling:
对于feature map中的一个像素,找到其水平方向和垂直方向的最大值并相加,作为这个点的置信。
Cascade corner pooling
corner pooling往往对边缘信息过于敏感,那么本文就使用cascade方式--类似两个corner一起用,来尽可能获取更多的物体中心信息

比如对top-left点:找到右侧最大值点A,再在A点向下找最大值B点;找到下方最大值C点,再在C点向右找最大值D点。最后top-left点=A+B+C+D。
两种pooling统一起来:
Focal Loss
Focal loss主要是为了解决one-stage目标检测中正负样本比例严重失衡的问题。
CrossEntropy Loss
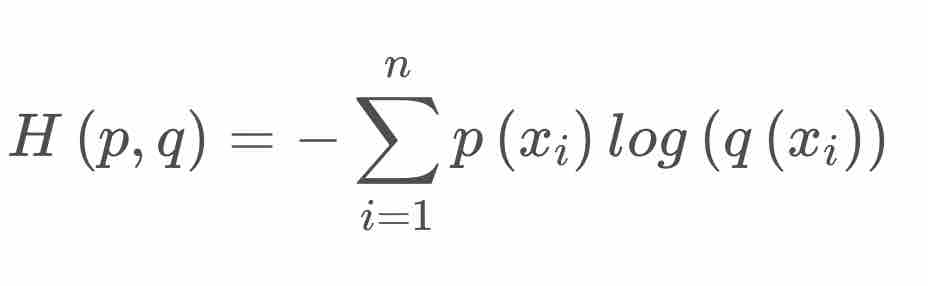
对于二分类来说则为:
\(Loss = -(y*log(y')+(1-y)*log(1-y'))\),其中\(y\)为ground truth,如果为真则为1,否则为0,其中\(y'\)为经过激活函数后的输出,在\(0-1\)之间。
在大量样本中,大多数样本都能被轻易分出,而对于能轻易分出的样本(即正样本高\(y'\),负样本低\(y'\))都造成Loss过小,收敛太慢。
Focal Loss即是对此进行了改进:
\(\begin{equation*}Focal Loss = \end{equation*} \begin{cases} -\alpha(1-y') ^\gamma logy' \quad y = 1\\ -(1-\alpha)y' ^\gamma log(1-y')\quad y = 0 \end{cases}\)
加入\(\gamma\)使得对于正样本高概率时loss降低,对于负样本低概率时loss降低(即概率趋近于0.5,不确定时的loss权重增加)
加入\(\alpha\)来平衡正负样本之间的数量差距。