AdaBoosting
Boosting & Bagging
Bagging是传统算法常常采用的方法:
- 从原始sample中用Bootstraping(类似cross-validation)选出n个样本,进行k次。
- 分别对k个训练集训练得到k个模型
- 加权得到最终模型
- 当算法结果不稳定时使用(训练集、测试集对结果影响大)
->Bagging可能出现多个模型对同一样的sample都分类错误
->不能并行所有model的训练而要串行(每次关注之前训练不当的地方)
AdaBoosting
- 在整个数据集上训练model(h1)
- 对h1表现好的sample降低权重,对h2表现不好的sample增加权重,训练model(h2)
- repeat
AdaBoost
如何实现AdaBoosting呢?
加权误差
一般 \(error = \Sigma _{y_i \neq h(x _i)} 1/n\),但是在对样本进行加权后 \(error = \Sigma _{y_i \neq h(x _i)} w _i\)。这就使得训练时模型被迫去关注权重更大(之前分类失败)的sample。
如何找弱分类器呢?
决策树桩
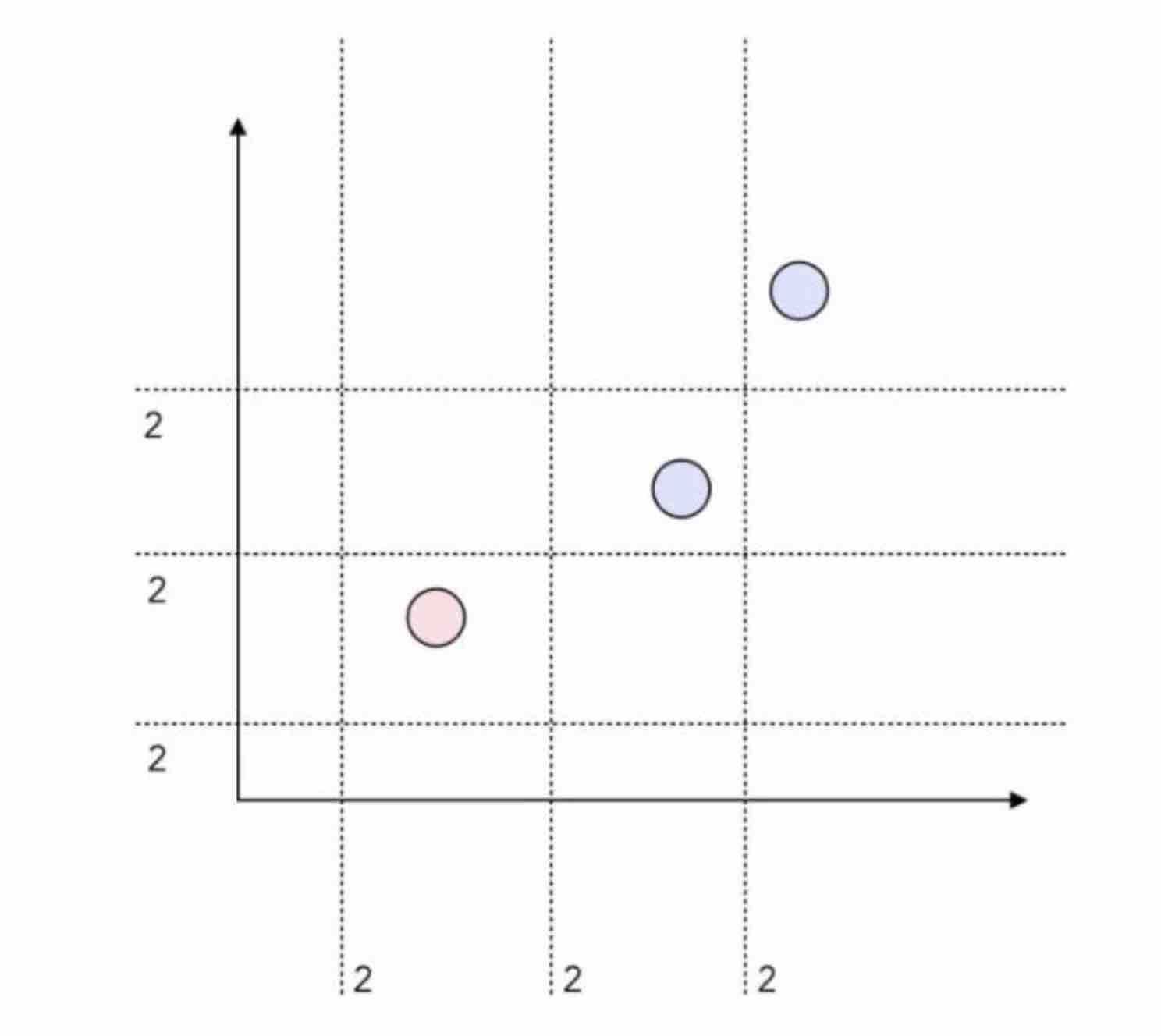
上图中简单的情况,有12种树桩组合。
我们可以对上面的情况做 12 种可能的「测试」。每条分割线边上的数字「2」简单地表示了这样一个事实:位于分割线某一侧的所有点都可能属于 0 类或 1 类。因此,每条分割线嵌入了 2 个「测试」。
针对不同的问题首先要选好弱分类器h,在迭代的过程中每次选择对当前(加权后)sample分类最优的弱分类器作为基本分类器进行融合。
- AdaBoost不需要先验,同时不容易过拟合,同时不依赖弱分类器效果(可以自由分配权重)。
- AdaBoost错误样本权重指数上升--容易受噪音干扰