SVM(Support Vector Machine)
Margin

从margin引入,优化理论告诉我们如果我们能找到更大的margin,那么理论上分类器表现就会更好,SVM简单来说就是通过不断迭代找到更好margin的算法。
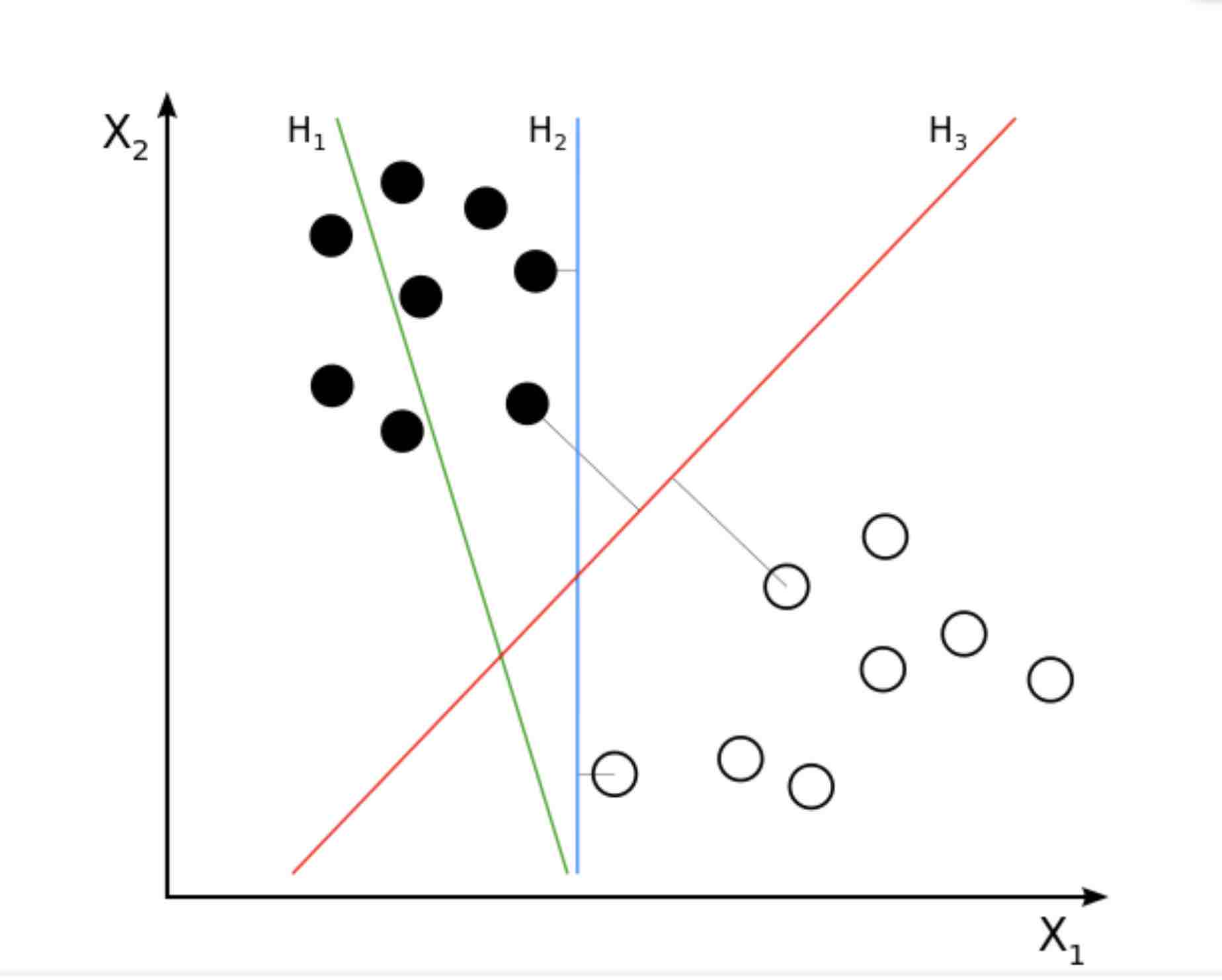
上图H1,H2,H3三个分类器,由margin可以看出来冥想H3更好(这也符合人的一般直觉)。
Linear Seperatable SVM
首先考虑所有sample本身线性可分。
Problem Definition
对于线性分类器的超平面为:\(X^TW+b=0\)。We define those with \(X^TW+b>1\) is labeled +1, which means geometrically the left-top part of the line is labeled positive.
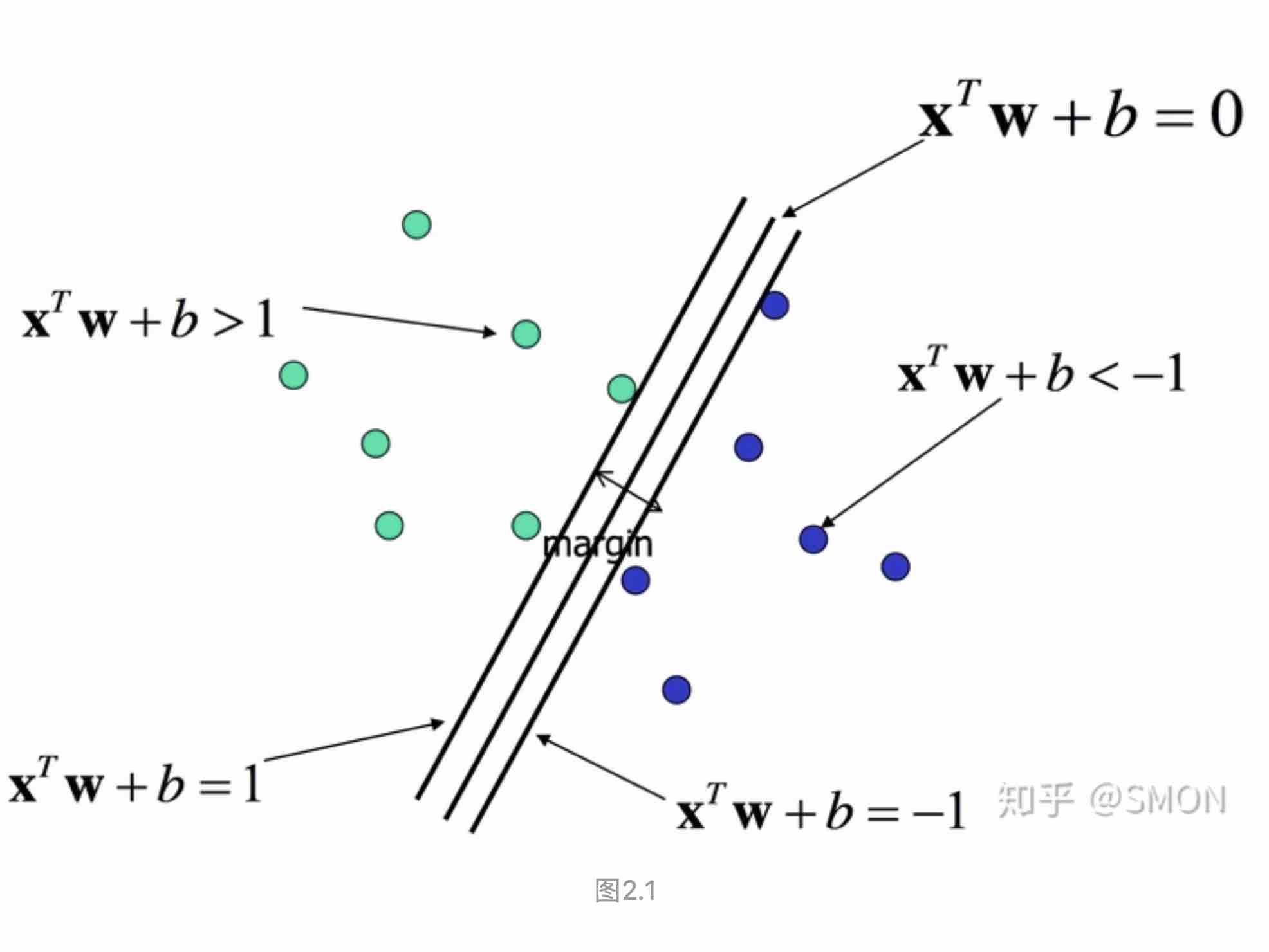
So we can see that \(margin = \frac{2}{||W||}\). We want to maximum margin which is same with \(min||W||^2\).
[primal problem]
The whole problem can be written as :
\(min||W||^2, \ st. y_i(X_i^TW+b)>=1\).
How to find W, b
If all the data is linear seperatable, those points that determine margin are called support vectors. For support vectors we have: \(y_i(X_i^TW+b)=1\). For other points, they have no influence on this algorithm so that this algorithm is called SVM.
NonLinear Seperatable SVM
Since the data is not linear speratable itself, we allow SVM has some mistakes--soft margin.
hinge loss
We will modify our objective function by adding hinge loss
(\(l_{hinge}=max(0,1-z), z=y_i(X_i^TW+b)\)).
Objective function: \(min \ ||W||^2+C\Sigma l_{hinge}\). C is hyper-parameter. If C->0, the model allows any mistakes--easily undercutting; if C->∞, the model is same with Linear Speratable SVM--easily overfitting.
[primal problem]
The whole problem can be written as:
\(min||W||^2+C\Sigma_i\xi_i, \ st.y_i(X_i^TW+b)>=1-\xi_i,\xi>=0\).
What if the sample is totally nonlinear seperatable?
Kernel
Introduce Lagranginan function and we get dual form of primal problem:
\(min_{\alpha}\Sigma_i^n\Sigma_j^n\alpha_i\alpha_jy_iy_j(X_i\cdot X_j)-\Sigma_i^n\alpha_i. \ st. \Sigma_i^n\alpha_iy_i=0, \ 0\leq\alpha_i<C\).
We can choose proper kernel \(K\) to replace \((X_i\cdot X_j)\).