Regularization in Deep Learning
Regularization
本来想自己写的,但是这篇文章写得太好了,几乎没有死角,所以就在以下简单写写补充的内容好了。
What is L1, L2 regularization
Overfitting
VC dimension is a measurement of model complexity. VC dimension \(\alpha\) # of model parameters.
Depress overfitting => Limit model complexity => Limit VC dimension => Limit number of model parameters => Dropout/Regularization (Dropout can also been seen as a special regularization)
L0 norm = number of non-zero parameters.
It would be a good idea to add L0 norm to the Loss function.
Lagrange function
The target function is: \(min_{w}Loss(w, X, y) \ st.||w||_0<=C\).
It is a optimization problem => Lagrange function: \(argmin_wLoss(w,X,y)+\lambda(||w||_0-C)\)
New target function is: \(min_wLoss(w,X,y)+\lambda||w||_0\)
And L1 norm and L2 norm can be seen as a kind of approximation of L0 norm. It also transform a non convex problem to a convex problem.
From another point of view, L1 L2 norm limits the range of parameters (but not just the number of parameters)
MAP--limit model complexity by adding prior on w
Here is the log maximum function of a linear model \(y=Xw\) \[ MLE:L(w) = logP(y|w,X) = log[\prod_i^NP(y_i|w,X_i)] \] If the model is biased: \(y=Xw+\epsilon, \epsilon \in N(0,\sigma^2)\), \(maxMLE <=> minMSELoss\)
Let's review MAP \[ MAP = P(w|X,y) = \frac{P(w,X,y)}{P(X,y)} => P(X,y|w)P(w)=>P(y|X,w)P(w) \] notice that the last step is a little bit tricky, so here is my understanding: \[ P(X,y|w)P(w)=P(y|X,w)P(w,X)=P(y|X,w)P(X)P(w)=>P(y|X,w)P(w) \] \(w\) is independent from \(y\) but \(w\) is dependent from \(x\).
Then \(maxMAP=>max(logMAP)=max(logP(y|X,w)+logP(w))\).
The former part is same with MLE, next part will be discussed below.
L2 norm
Suppose \(P(w) = N(0,\sigma^2) = \frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{w^2}{2\sigma^2}}\), \(logP(w) => -||w||_2^2\)
Assume weights are in Guassian distribution <=> L2 regularization
L1 norm
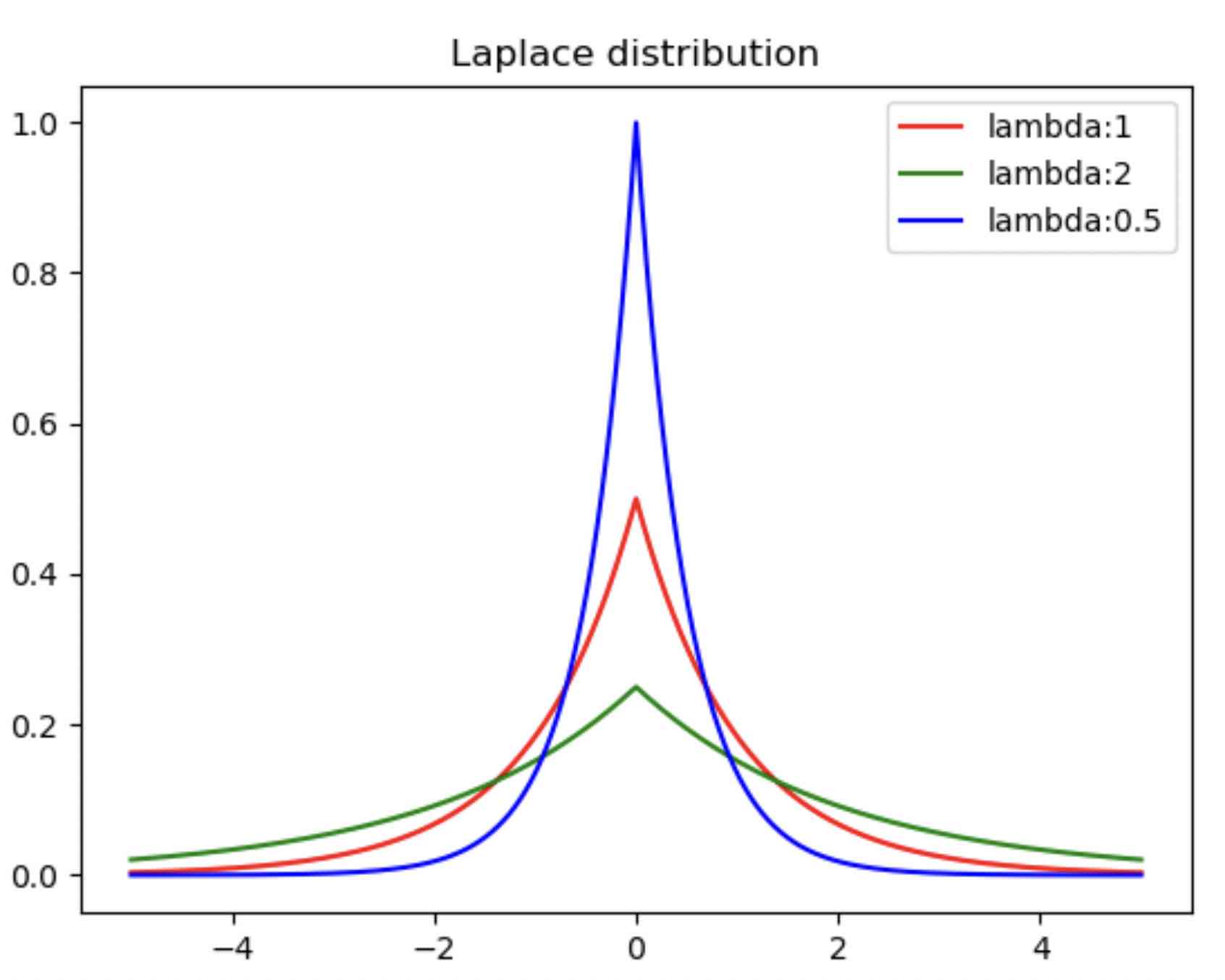
Suppose \(P(w) = Laplace(0,\lambda) = \frac{1}{2\lambda}e^{-\frac{|w|}{\lambda}}\), \(logP(w) => -||w||_1\)
Assume weights are in Laplace distribution <=> L1 regularization
Weight decay
L2 norm can also been seen as a method of weight decay--when updating parameters, shrink parameters then update.
L1-norm vs. L2-norm
在深度学习网络中,该怎么选择Regularization呢?
L1 norm if capable of producing a sparse result, which is really important for large network. (but a sparse results means L1 norm throw away some features)
L2 norm assumes \(w\) in Gaussian distribution. According to Law of large number, it should be more robust than L1 norm.
Why not L0-norm
事实上L0并不是严格意义上的norm,但是L0可以很好地体现出参数的稀疏性,因此来限制模型复杂度非常合适。那么有什么问题呢?
L0 penalty不是凸优化问题--非凸优化问题会带来什么问题呢?此问题的深入理解仍需后续。
L0 norm的计算为NP-hard问题。这一点上我没有找到严格意义的证明,但是就我个人的简单理解--神经网络参数往往使用float32,而float本身是有精度误差的,想要判断数值比较float==0本身就是一件很困难的事情,还不如直接进行数值运算。