Dive into FasterRCNN
发展顺序
本文仅关注从R-CNN、SPP-Net(2014)至Fast R-CNN、Faster R-CNN(2015)的图像分割技术。
R-CNN
Region-CNN
Efficient Graph-Based Image Segmentation
主要目的也就是将图像(image)分割成若干个特定的、具有独特性质的区域(region),然后从中提取出感兴趣的目标(object)。
为了找到有意义的图像区域,我们很容易想到根据灰度gradient变化,但是会产生下图问题:

左侧图像灰度变化均匀,右侧图像仅有部分区域有灰度变化。上图的例子告诉我们不能使用灰度的变化作为分割依据,也不能使用单一的灰度阈值来作为分割的评判标准。
Graph-based image & minimal spanning tree
首先我们要将图片以graph图论的形式表示,graph的vertex为image的每个像素点,graph的edge一般定义为像素点的相邻关系,权重为灰度差或者距离等。
如何分割这个tree,也就是合并像素点呢?这里用到的是最小生成树,简单说就是尝试找出一个tree结构使得所有的点都能被联通,并且使tree的edge权重和最低。直观地看就是尽可能使相似的像素点结合在一个subtree上。最终结果可以大大减少图的edge数量。
具体举个例子:
图像(image)的图(graph)表示为G=(V,E),每个像素点代表图的一个顶点vi ∈ V ,相邻(相邻的像素点,可以是像素的4邻域也可以是8邻域)的两个像素点构成一条边(vi, vj) ∈ E。图每条边的权值是像素与相邻像素的关系(灰度图的话是灰度值差的绝对值,RGB图像为3个通道值差平方和开根号),表达了相邻像素之间的相似度。权值越小,表示像素点之间的相似度就越高,反之,相似度就越低。
Graph Cut
将每个节点(像素点)看成单一的区域,然后进行合并。 (1) 对所有边根据权值从小到大排序,权值越小,两像素的相似度越大。 (2) S[0]是一个原始分割,相当于每个顶点当做是一个分割区域。 (3) 从小到大遍历所有边,如果这条边(vi,vj)的两个顶点属于不同的分割区域,并且权值不大于两个区域的内部差(区域内eege最大权值),那么合并这两个区域。更新合并区域的参数和内部差。
最后对所有区域中,像素数都小于min_size的两个相邻区域,进行合并得到最后的分割。
Selective Search
有了上述的基于图的图像分割技术,接下来我们可以讨论如何生成region proposal。
最简单的方法当然是用不同大小的框去遍历图像,然后把所有框出来的图像都让分类器处理,但是这样明显性能开销太大,那么就可以模仿上述的image segmentation技术,以合并类似图像块的方式得到region proposal。
Implementation
step0:生成区域集R,基于《Efficient Graph-Based Image Segmentation》 step1:计算区域集R里每个相邻区域的相似度S={s1,s2,…} step2:找出相似度最高的两个区域,将其合并为新集,添加进R step3:从S中移除所有与step2中有关的子集 step4:计算新集与所有子集的相似度 step5:跳至step2,直至S为空
R-CNN实现
R-CNN全称为Regions with CNN features,基本思想就是由基础的AlexNet直接处理特征滑窗进化为先选取出proposal region,然后再直接处理proposal region(proposal region的数量由人为控制)来判断到底是背景还是前景。
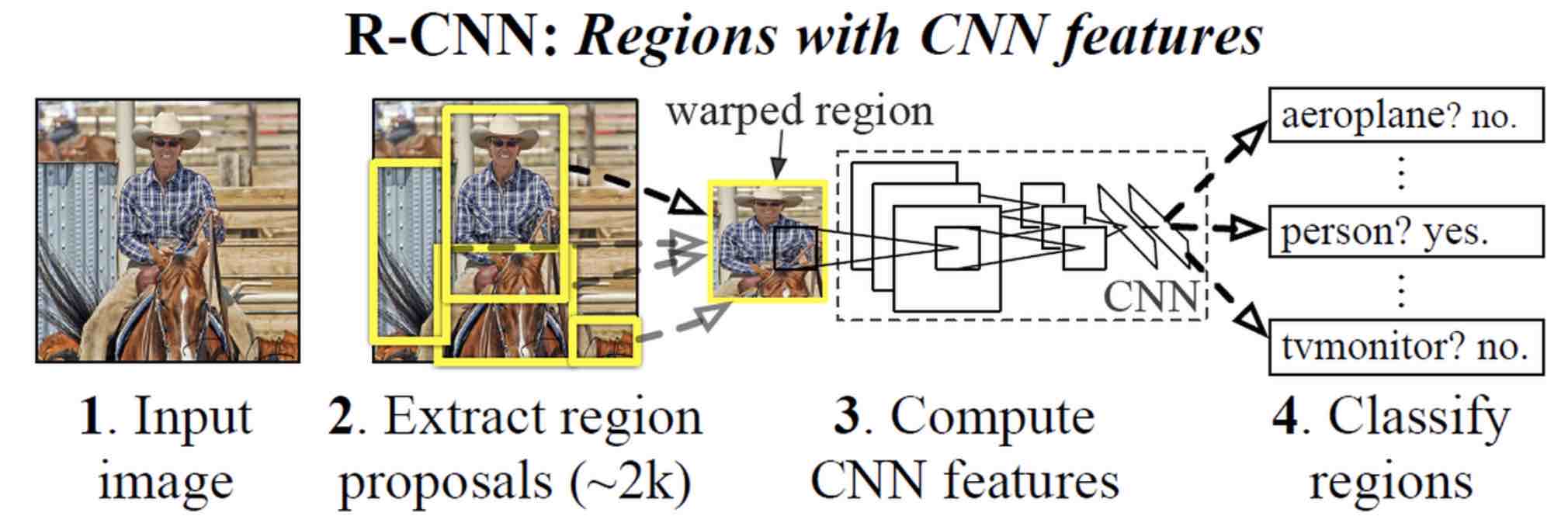
RCNN的输入为完整图片,首先通过区域建议算法产生一系列的候选目标区域,其中使用的区域建议算法为Selective Search。然后对于这些目标区域候选提取其CNN特征,并训练SVM分类这些特征。最后为了提高定位的准确性在SVM分类后区域基础上进行BoundingBox回归。
AlexNet 细节
R-CNN使用的AlexNet为了加速训练使用了fine tune。AlexNet的参数并不是完全随机初始化的,而是先用AlexNet+Classifier训练了一个单一物体分类的神经网络,然后直接把这个网络的参数作为初始值使用。这样可以使网络的参数在初始化时就能具有一定的分类意义,大大加快训练速度。
同时还要注意AlexNet只能处理224x224的图像大小,为了能够使region proposal能够适应这个大小,论文使用原图像类填充这个范围(在原图像填充、原图像均值填充、直接拉伸,三种方法中为最优)。
如何训练分类器SVMs
CNN已经能很好地提取出特征了,经过实验,使用FC层作为最后的特征输出。
Hard mining
在tag region proposal时,R-CNN将IOU(重合度)>50%的都作为正样本(标注对应tag),但是实际上正样本实在太少,于是又将IOU<30%的设置为负样本(标注为background),这种做法称之为Hard Mining
非极大值抑制
region proposal有将近2k个区域,有很多重合。首先把IOU超过某个阈值的几个区域取出来,然后比较他们由SVM得到的置信概率,仅取最大置信。
Bounding Box
bounding box回归,目标是使得预测的region proposal向groundtruth窗口相接近。
窗口一般使用四维向量(x,y,w,h)表示,x y表示框的中心位置,w h表示框的weight height。
Bouding box目标是寻找一种关系使得输入原始的窗口 P 经过映射得到一个跟真实窗口 G 更接近的回归窗口\(\hat{G}\),即:给定(Px, Py, Pw, Ph)寻找一种映射f,使得f(Px, Py, Pw, Ph)=(\(\hat{G_x}\) \(\hat{G_y}\) \(\hat{G_w}\), \(\hat{G_h}\)) 并且(\(\hat{G_x}\) \(\hat{G_y}\) \(\hat{G_w}\), \(\hat{G_h}\))≈(\(G_x\),\(G_y\),\(G_w\),\(G_h\))。
很直观的一个想法是先平移然后缩放:
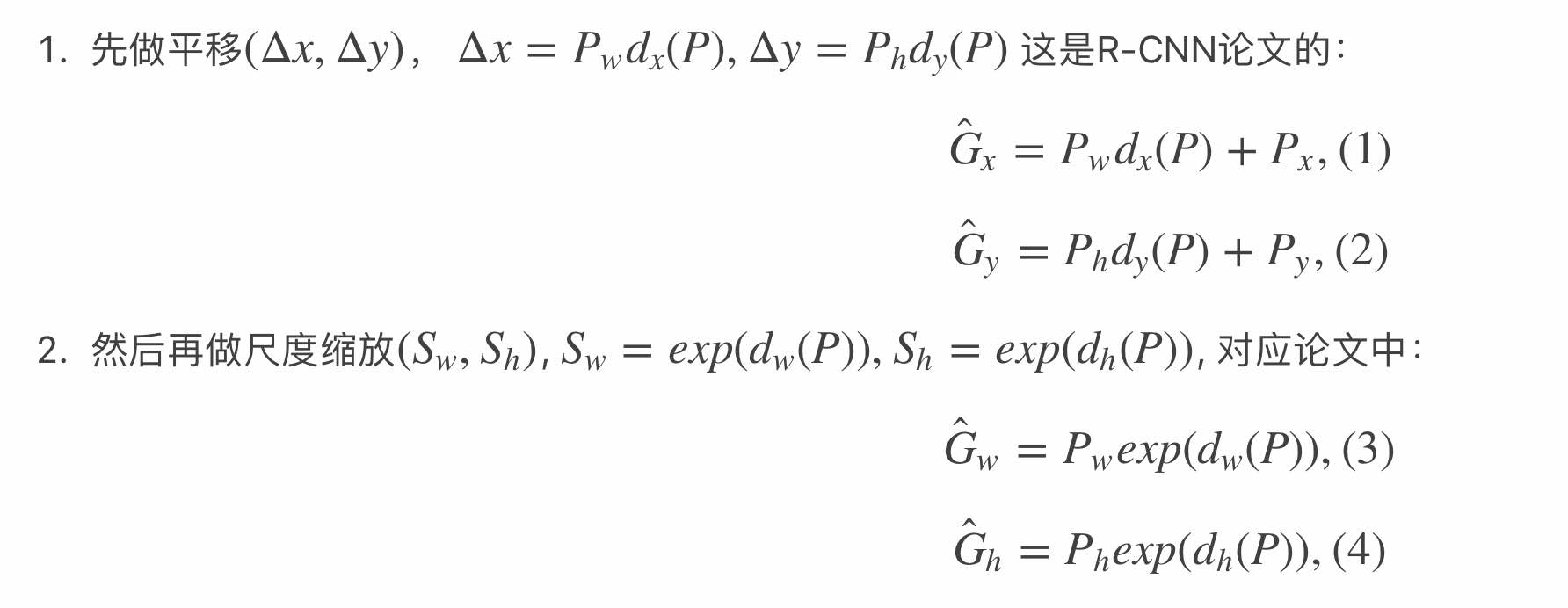
为了能够得到\(\hat{G}\),我们需要四个参数:
\(d _x(P), d _y(P), d _w(P), d _h(P)\),这四个对应的ground truth定义为:
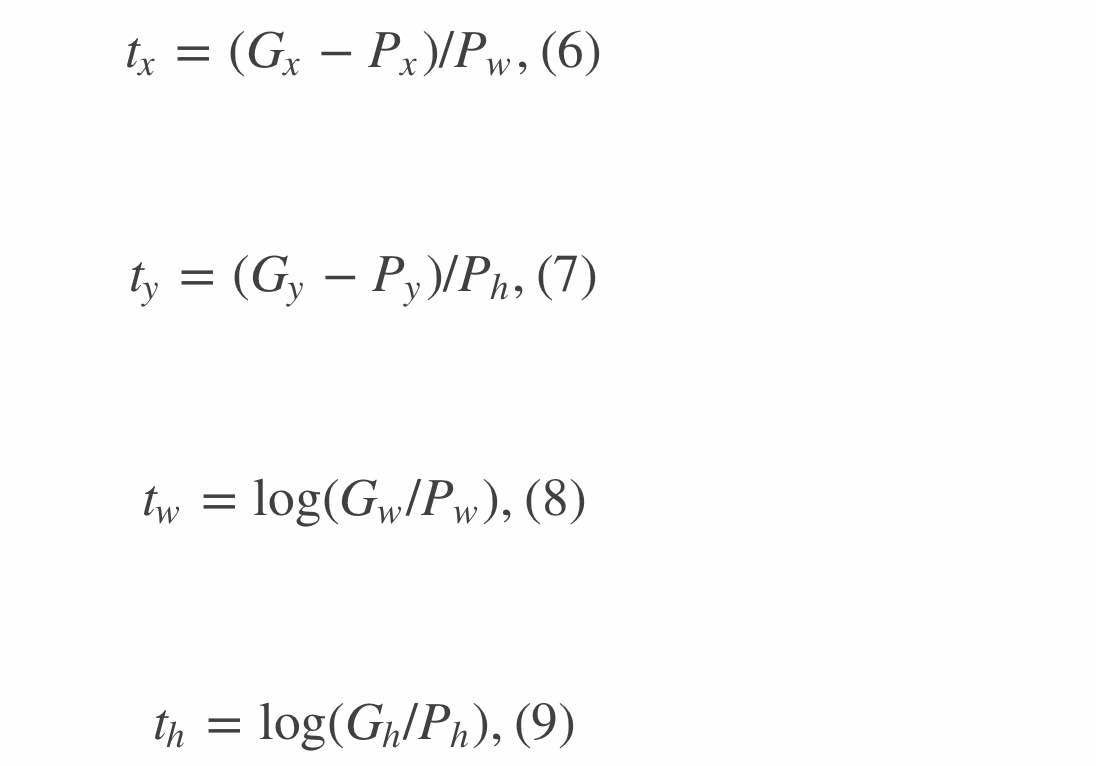
由于这个线性回归网络是建立在AlexNet之后的,所以input实际为一个4096维的特征向量(记为\(Φ _5(P)\)),那么目标函数(预测值)就可以写作:\(d _∗(P)=w ^T∗Φ _5(P)\),其中\(*\)意为(x,y,w,h)参数。
Loss function可以直观地定义:
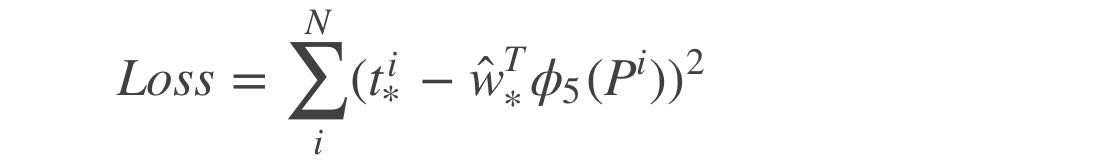
加入\(\lambda ||w _*|| ^2\)抑制过拟合:
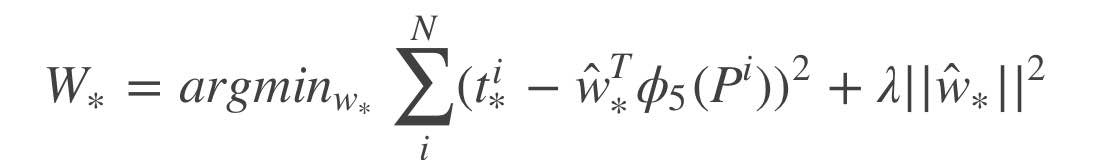
那么上述公式为什么要设置的这么复杂?
- \(\Delta x/\Delta y\):这里不能将\(t _x\)简单设为\(G _x - P _x\)是为了满足CNN的尺度不变性:同样的图经过缩放后理论上特征不会变,如果不用\(/P _w\)那么显示图片的大小就会有影响。
- \(S _w/S _h\):这里一定要用\(exp\)的原因是因为学习的结构是不受控的\(d _w(P)\)可能为负数,所以很直观地想到用\(exp\)保证参数不为负。
还有一个很关键的问题:为什么可以用线性拟合?
这里是有一个限制的--region proposal 与 ground truth 相差较小时(R-CNN设置为IOU>0.6)才能认为是线性变化。
很直观地去理解:首先要明确线性拟合的是什么?是input特征向量和ouput最后的\(d _*(P)\)(即对box的修正)。那么在region proposal和ground truth接近时,可以假定为region proposal约接近ground truth,input的特征向量也越接近,导致最后output也越趋近于0(无修正),在足够小的范围内用线性来理解是可行的。
Note
为什么不直接先用AlexNet分好类而是要用SVM呢?
R-CNN尝试过,但是精度下降了,可能是由于在tag region proposal时IOU>50%的限制过于宽松,但是如果考虑放开限制,数据量却会大大下降,远远不能满足需求
SPPNet
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
R-CNN->SPPNet
R-CNN的问题:
- Selective Search对于每幅图片产生2K左右个region proposal,也就是意味着一幅图片需要经过2K次的完整的CNN计算得到最终的结果。
- 对于所有的region proposal放缩到224*224会导致几何形变。
其实CNN的卷积核可以适应不同大小的输入,但是最终的FC层却要求固定大小,从而使得CNN的输入为恒定大小。为了解决这个问题,很直接的一个思路就是在FC之前加一层pooling,保证输入到FC的feature数稳定。进一步为了解决对一幅图片过多次提取feature,SPPNet提出SPP(Spatial Pyramid Pooling)。
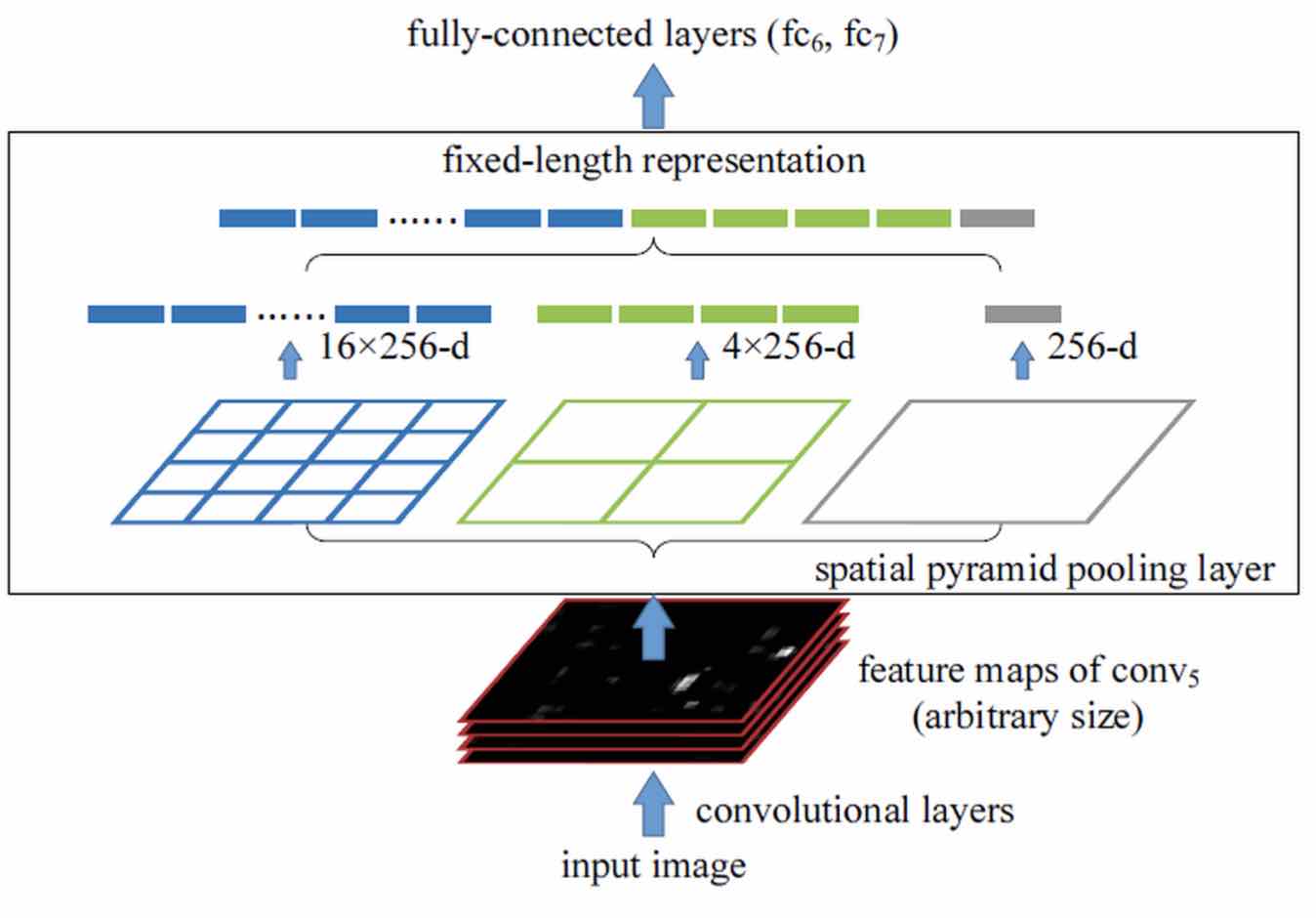
Input image -> Conv -> SPP -> FC
SPP
输入到SPP的feature大小为H*W*255(Conv最后一层有255个filter)。
SPP将一层feature map按照不同的大小多次划分处理:先划分为1、4、16块,然后进行MaxPooling,最后拼接在一起(得到(16+4+1)*256大小的feature vector)。
Training
由于当时的学习框架都固定input大小,所以SPPNet先固定一个inputsize(对输入缩放得到),训练一个epoch后固定参数,改变inputsize训练。
SPPNet的网络特性使得训练时的inputsize改变非常容易实现(多尺度训练),同时针对同一个尺度,SPP也保证了训练特征有多尺度的特性。
Testing
在测试时,由于SPP可以接受任意大小的输入,因此接受到region proposal时,想办法将其映射到feature map上,然后仅对这一块feature map进行空间金字塔池化就可以得到固定维度的特征用以训练CNN了。这样子我们就可以定位每一个region proposal的feature在整个图片feature map的位置,从而只需要对图片特征提取一次。 映射方法:

比起R-CNN,SPPNet的精度有所下降,但是速度得到了极大的提升,特别是在多尺度图片处理中,而且SPP的思想也可以在几乎所有CNN上推广。
Fast R-CNN
SPPNet->Fast R-CNN
与R-CNN一样,SPPNet同样需要多阶段训练:预训练CNN网络->Fine Tune->SVM->Bounding Box
Fast R-CNN希望能简化这一流程。
网络结构
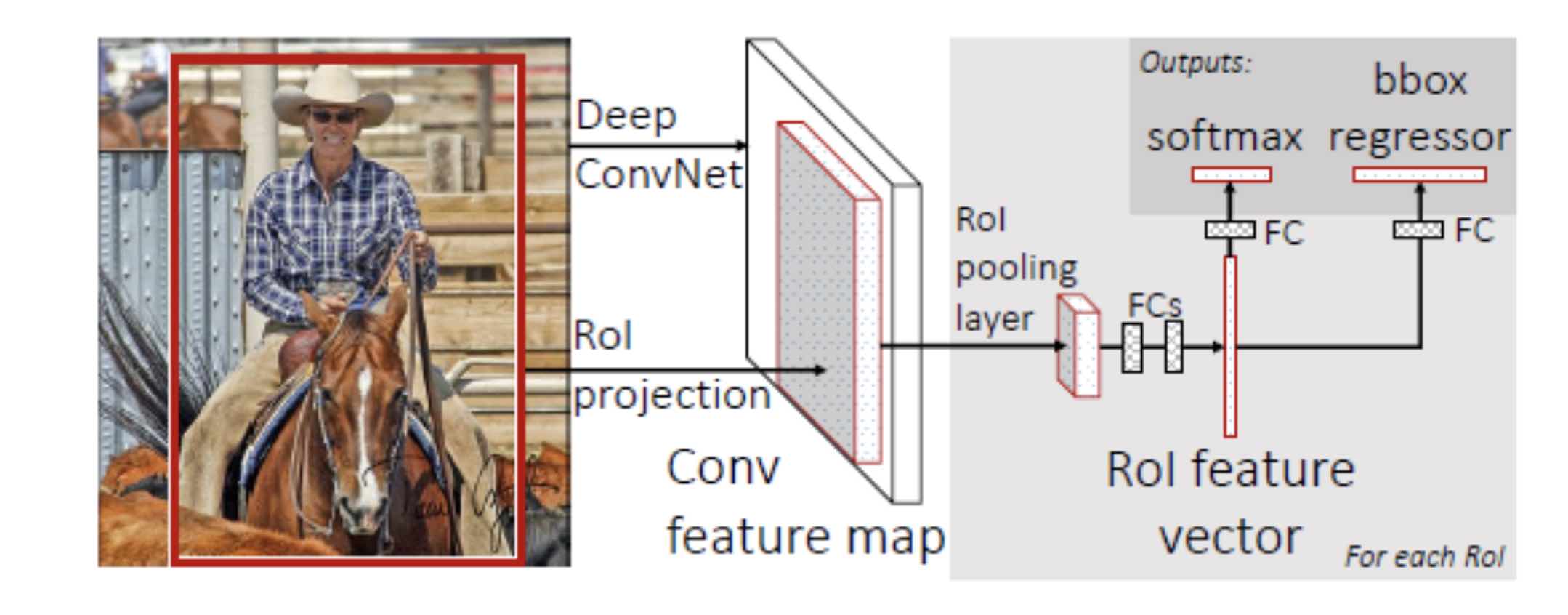
Fast R-CNN吸取了SPPNet的优点:
先对整张图片经过ConvNet提取特征得到Conv feature map,然后根据不同的RoI(region of interest,即为由selective search得到的region proposal)经过RoI projection找到Conv feature map中RoI对应的feature map。为了使网络能够应对不同大小的RoI,feature map需要经过RoI pooling得到固定大小的feature map作为FC输入(Fast R-CNN中FC输入为512*7*7)。
注意SPP能提取多尺寸特征,RoI Pooling是单一尺度的。
Softmax
二元分类-Logistic Regression
简单来说softmax是logistic regression的一种推广。
用logistic regression和linear regression一起对比可以更直观地看出来核心区别:

关键核心在于logistic使用了cross entropy(两个分布的近似情况)来作为衡量net好坏的依据。
比起Generative model(假定某个概率分布,去求最大似然估计),Logistic Regression作为Discriminative model的先验信息更少,因此效率更高,但是不能应对隐变量的存在。
多元分类-Softmax Regression
输入x后如何得到y:
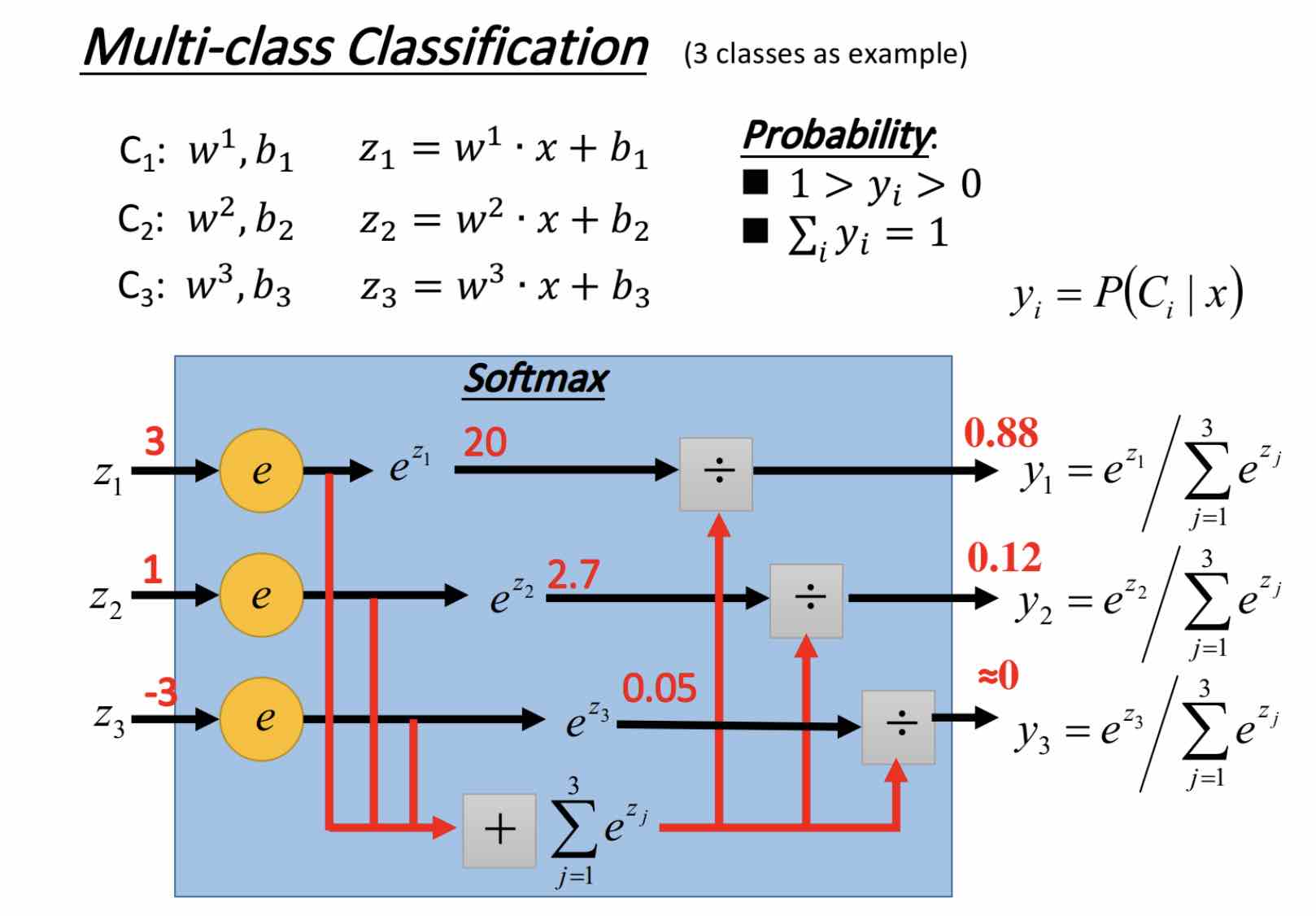
Softmax的意义在于可以归一化output到0~1之间,同时可以强化最大值/概率(\(y _i为input \ x 为C _1 的概率\))。
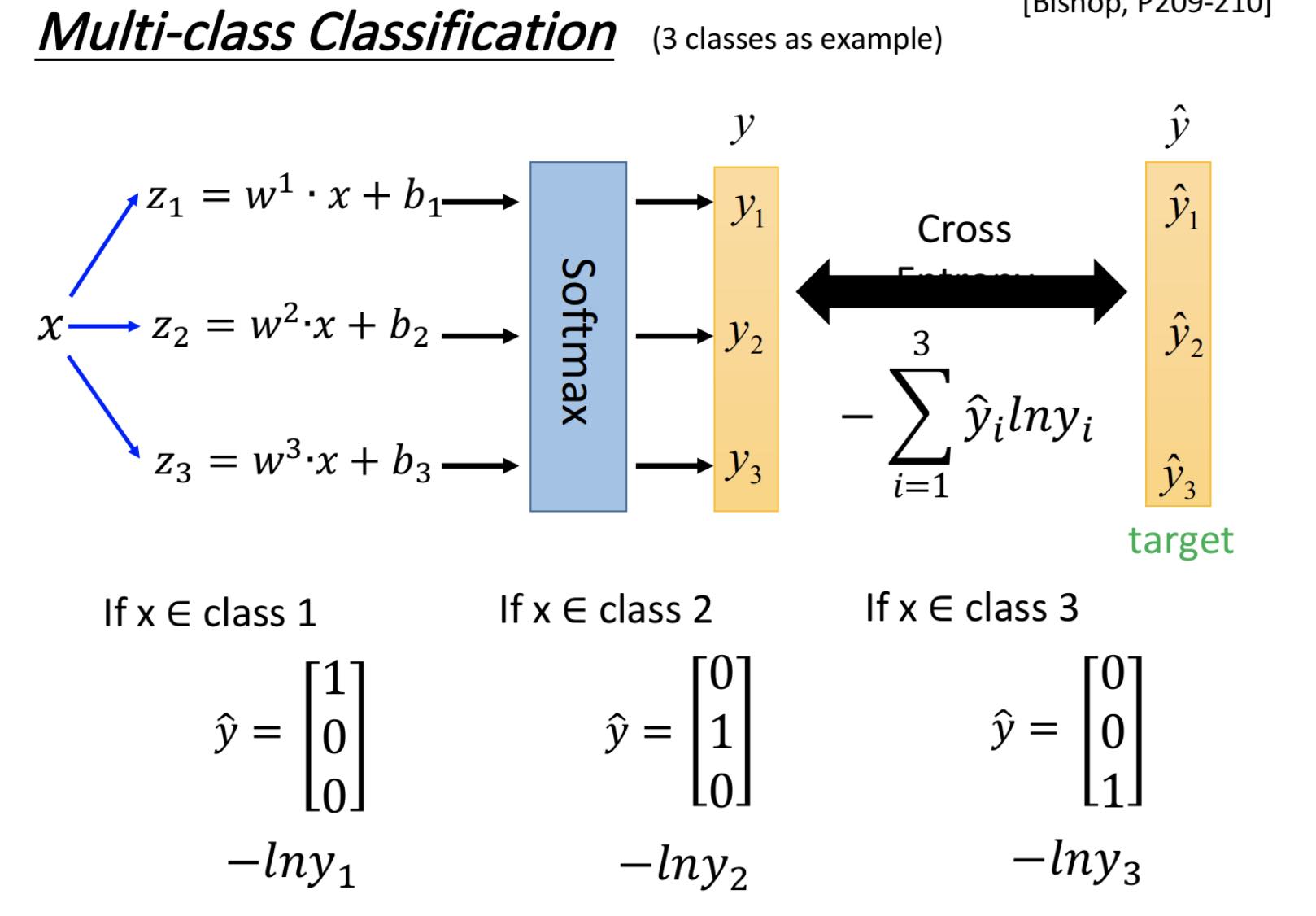
通过上述操作,可以计算\(y\)和\(\hat{y}\)之间的cross entropy。
继续Faster R-CNN
Fast RCNN主要有3个改进:
- 卷积不再是对每个region proposal进行,而是直接对整张图像,这样减少了很多重复计算。(原来RCNN是对每个region proposal分别做卷积,因为一张图像中有2000左右的region proposal,肯定相互之间的重叠率很高。)
- 用ROI pooling进行特征的尺寸变换,因为全连接层的输入要求尺寸大小一样,因此不能直接把region proposal作为输入。
- 将regressor放进网络一起训练,每个类别对应一个regressor,同时用softmax代替原来的SVM分类器。仅一层网络,比训练多个SVM分类器效率更高。
note:对于一般的训练器,最后的FC层往往占比很小(FC大小为最后分的类的个数),但是对于Fast R-CNN,FC的开销很大。为例解决这一问题,作者使用了SVD分解(奇异值分解)。
Training
由于一个网络内有多个任务,Loss Function也因此做出了改变:
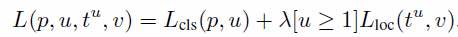
Loss Function实际上为Loss of classification + Loss of location(Bbox)
Faster R-CNN
卷积神经网络部分运行在GPU上,而selective search运行在CPU上,因此在使用中selective search成为了巨大的阻碍。为此提出了Region Proposal Network(RPN),用GPU实现快速的区域建议,让测试近乎实时。
在之前的算法中region proposal与后续的detection往往是分开进行的。region proposal一般分为两类:基于超像素(一系列位置相邻且颜色、亮度、纹理等特征相似的像素点组成的小区域)合并;基于滑窗。
那么为了让两个任务融合在一起,Faster R-CNN用了更加直白的想法--既然在原image上用滑窗开销太大,那么在feature map上用滑窗不就节省计算了吗?这也就是RPN。但是因为feature map上的滑窗相对于原image上的滑窗精度更低,RPN给每一个滑窗都加上了回归(Bbox)来使窗口更加精准。
Net Structure
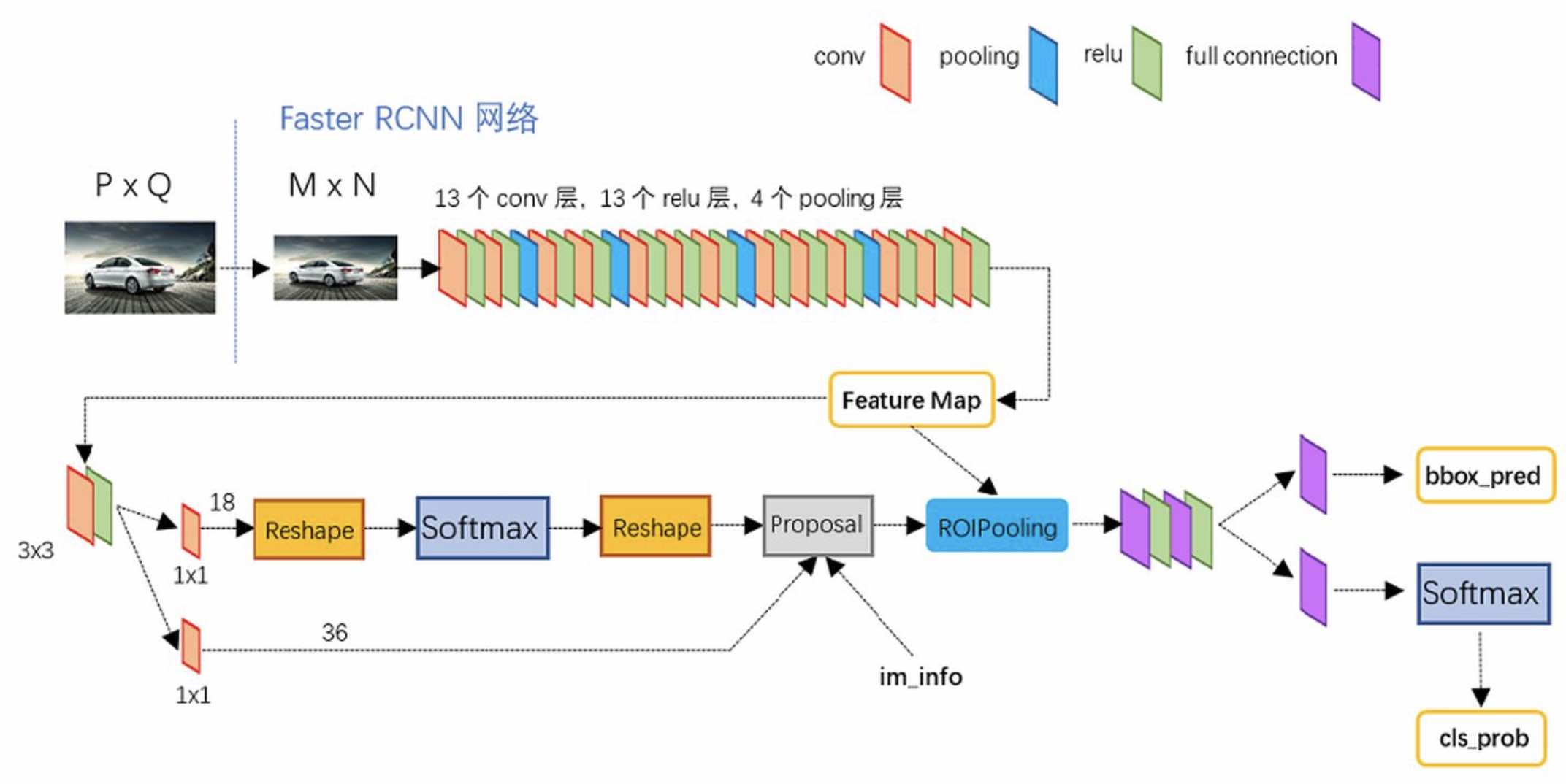
输入P*Q大小图片--缩放为M*N大小--经过Conv--Feature Map
Feature Map--经过RPN输出Region Proposal--找出Feature Map对应区域(即为ROI)--同Fast R-CNN
Region Proposal Networks(RPN)
Anchors
要解释RPN,先要解释Anchors。
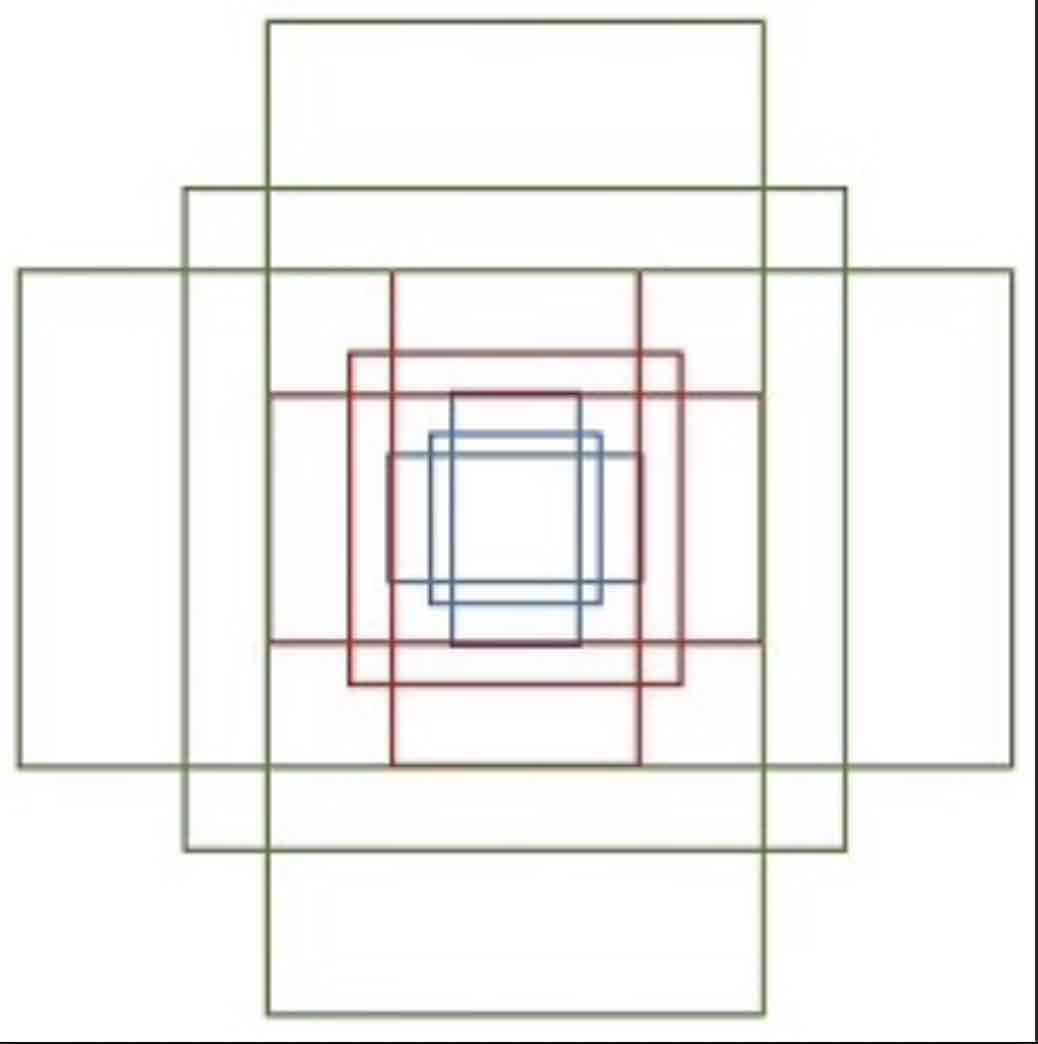
原文中的anchors即为大小不同的9个矩形框,每个矩形框用4个数据表示(对角两个点坐标)。假设CNN得到的feature map大小为w*h,那总的anchors个数为9*w*h,9为上述的9种anchors。说白了就是用这些anchor把feature map全部遍历一边,根据对应的anchor矩形框的区域可以计算出原图像上对应的区域(也就是在原图像上间隔地用更大的尺度遍历一遍)。
RPN
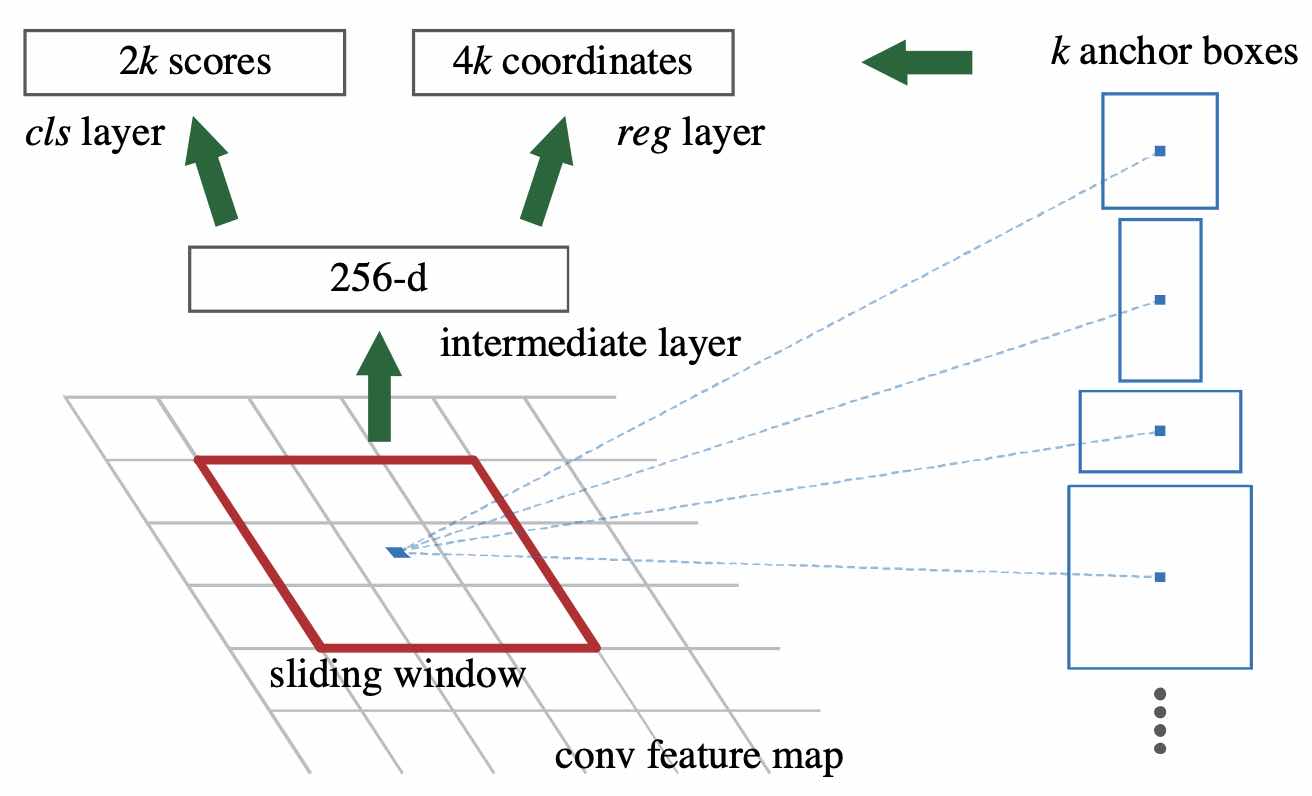
CNN的最后输出为265层(即265张feature map),首先经过3*3卷积最后输出还是265层(265-d)。
对于分类层(cls layer)中,在conv5 feature map中每个点上有k个anchor(原文如上k=9),而每个anhcor要分foreground和background,所以每个点由256-d feature转化为cls=2k scores。
对于框位置的回归层(reg layer),每个anchor都有4个偏移量,所以reg=4k coordinates。
RPN的最终输出scores和coordinates。
全部anchors拿去训练太多了,训练程序会在合适的anchors中随机选取128个postive anchors+128个negative anchors进行训练。
RPN其实是在原图尺度上,设置了候选Anchor。然后用cnn去判断哪些Anchor是前景,哪些是背景。本质上是二分类器。
在此之后网络有两条路径,先说上面一条(->1x1 conv->reshape->softmax->reshape)
Softmax找出前景anchor
经过1x1 conv之后的输出为2k层(图中为18,对于k=9)。reshape层是为了应对caffe特殊的数据存储方式。之后通过softmax进行二分类,找出前景(positive anchor)和背景(negative anchor)
Proposal Layer forward(caffe layer的前传函数)按照以下顺序依次处理:
- 生成anchors,利用Bbox输出的结果修正anchors。
- 按照输入的foreground softmax scores由大到小排序anchors,提取前N个。
- 限定超出图像边界的foreground anchors为图像边界。
- 剔除非常小的foreground anchors。
- 进行nonmaximum suppression(即相交超过一定程度的anchors之间保留softmax score最高的一个)。
- 再次按照foreground softmax scores由大到小排序,提取前N个结果作为proposal输出。
- 之后输出proposal=[x1, y1, x2, y2](对角坐标)。
Train
Loss Function
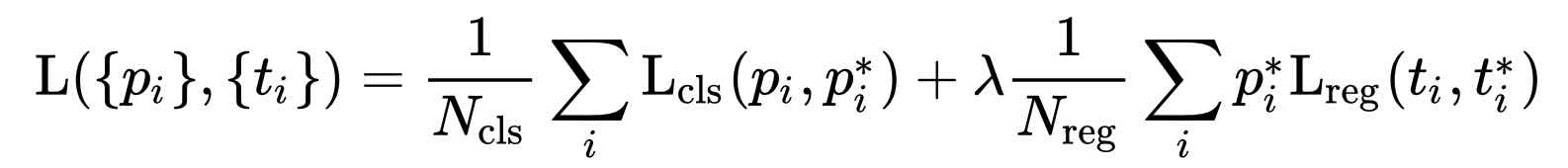
\(i\)表示anchors index
\(p _i\)表示foreground softmax probability
\(p _i ^*\)代表对应的ground truth predict概率(即当第i个anchor与ground true间IoU>0.7,认为是该anchor是foreground,此时\(p _i ^* = 1\);反之IoU<0.3时,认为是该anchor是background,此时\(p _i ^* = 0\);至于那些0.3<IoU<0.7的anchor则不参与训练)
\(t\)代表predict bounding box,\(t ^*\)代表对应foreground anchor对应的ground truth box。
\(\lambda\)的引入是因为\(N _{cls}\)和\(N _{reg}\)之间有一个数量级的差距,所以需要参数来平衡使两者对Loss的贡献类似。
L分为两部分 = cls loss(即rpn_cls_loss层计算的softmax loss) + reg loss(即rpn_loss_bbox层计算的soomth L1 loss,该loss中\(*p _i ^*\),因此只关心前景的loss)
其中
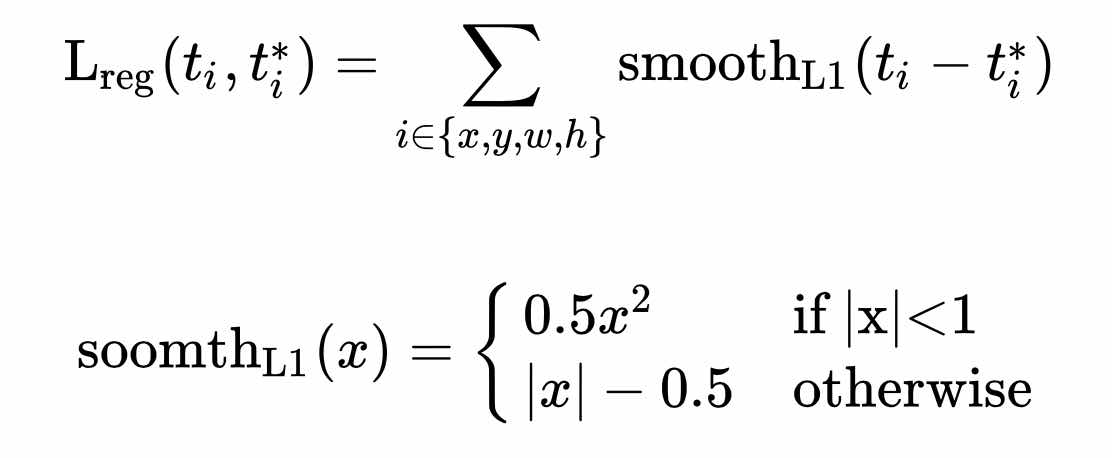
使用smooth L1 loss可以避免L2 loss造成的梯度爆炸。